The LLM-Augmented Search Catalog
The modern overlay: LLM-augmented query understanding, document enrichment, LLM-as-reranker, RAG with citation, evaluation.
About This Catalog
This is Volume 9 of the Search Engineering Series — an optional volume covering the LLM-augmented overlay on traditional search engineering. Where Volumes 1–8 cover production search engineering as a discipline independent of LLM integration, this volume covers the patterns for using LLMs throughout the search pipeline: query understanding, document enrichment, reranking, conversational synthesis (RAG), and operations. The volume's framing is that LLM augmentation is incremental — each stage of the pipeline can adopt LLM patterns independently — and that the traditional disciplines documented in Volumes 1–8 remain the foundation.
Why this volume is structurally optional. The eight-volume library is complete without it. Production search systems can be built, operated, and improved using only the patterns from Volumes 1–8; many production deployments don't use LLM augmentation at all, or use it only in limited ways. Volume 9 documents an overlay rather than a foundation. Teams that aren't ready to invest in LLM augmentation should skip this volume entirely; teams that are can use it as the reference for the specific patterns.
Why this volume is increasingly central despite being optional. The LLM-augmentation overlay has become the most active area of search engineering through 2024–2026. Conversational search interfaces, RAG-based knowledge bases, AI-augmented query understanding, semantic reranking, generative search synthesis — all of these are appearing in production deployments at scale. For consultants and engineers working with clients in 2025–2027, the question is rarely whether to consider LLM augmentation; it's where to apply it and how to operate it. This volume documents the patterns; the eight-volume foundation determines whether they can be applied competently.
Currency caveat. The LLM-augmented search field is evolving extraordinarily rapidly. Specific techniques, model capabilities, and operational patterns documented here will date faster than the material in Volumes 1–8. The patterns described aim for the durable underlying structure (retrieval + LLM, two-stage rerank, cascade architectures, cost-quality trade-offs) rather than specific model versions or prompt templates that change frequently. For current details, the practitioner should consult vendor documentation and recent practitioner writing.
Scope
Coverage:
- LLM-augmented query understanding: query rewriting, decomposition, expansion, HyDE (hypothetical document expansion), intent classification.
- LLM-augmented document processing: semantic chunking, summarization, metadata extraction, question generation for indexing.
- LLM-as-reranker: cross-encoder reranking, LLM-as-judge scoring, listwise reranking with off-the-shelf LLMs.
- Conversational synthesis and RAG: retrieval-augmented generation, citation preservation, faithfulness.
- Hybrid retrieval patterns: how LLM augmentation interacts with traditional lexical and vector retrieval.
- Evaluation for LLM-augmented search: faithfulness scoring, citation correctness, judgment at scale.
- Operations: cost management, latency tail handling, fallback patterns, drift detection.
Out of scope:
- Foundation model training and architecture. Covered by the broader ML / NLP literature.
- Pure conversational AI without retrieval (chatbots that don't consult external knowledge). Covered by the agentic AI series.
- LLM-based agent orchestration beyond search. Covered by the agentic AI series (Volume 10 on RAG patterns specifically).
- Prompt engineering as a discipline. Covered by general LLM literature; this volume uses prompts as artifacts but doesn't teach prompt design from scratch.
- Specific LLM provider operational details (API rate limits, billing models). These change frequently; refer to current vendor documentation.
How to read this catalog
Part 1 ("The Narratives") is conceptual orientation: what LLM-augmented search is; the pipeline framing showing where LLMs fit; RAG architecture in depth; evaluation in the LLM-augmented world; operating the augmented stack. Five diagrams illustrate the structural patterns.
Part 2 ("The Substrates") is the pattern reference. Each section opens with a short essay; representative patterns appear in the Fowler-style template with code artifacts where applicable. The patterns are designed to be adoptable incrementally — a team can adopt one or two patterns without committing to the full LLM-augmented stack.
Part 1 — The Narratives
Five short essays orient the reader to LLM-augmented search. The patterns in Part 2 assume the vocabulary established here.
Chapter 1. What LLM-Augmented Search Is
LLM-augmented search is the application of large language models to specific stages of the search pipeline. It is not the replacement of search engineering with LLMs — that would be a chatbot that hallucinates answers without grounding. It is the addition of LLM capabilities to the existing pipeline where the LLM's strengths (semantic understanding, generation, reasoning) complement the existing strengths of retrieval (scale, latency, recall).
The pipeline framing remains the foundation. Volume 1 documented the canonical search pipeline: query understanding → retrieval → ranking → presentation. LLM augmentation slots LLM calls into specific stages of this pipeline rather than replacing the pipeline itself. The query understanding stage might use an LLM to rewrite queries; the ranking stage might use an LLM to rerank candidates; the presentation stage might use an LLM to synthesize answers. The retrieval stage — the actual lookup of documents from the index — typically remains traditional (BM25, vector similarity, hybrid) because it has to be fast and cheap; LLMs are too expensive to run on every document for every query.
What LLMs add that traditional retrieval doesn't. Three capabilities are genuinely new. First, semantic understanding beyond what embedding models capture — LLMs can reason about query intent, ambiguity, decomposition in ways that improve recall and precision. Second, generation — producing natural-language answers, summaries, explanations grounded in retrieved content, which is impossible without an LLM. Third, in-context reasoning — the LLM can compare candidates, weigh evidence, follow multi-step logic that no retrieval model can do. Each capability has its place in the pipeline; recognizing where they help is the discipline.
What LLMs cost that traditional retrieval doesn't. Three costs are real. First, latency — LLM calls add 100ms to several seconds per query; even with streaming and caching, the latency budget is fundamentally different. Second, monetary cost — each LLM call has a per-token cost; at production query rates, the bill is non-trivial. Third, failure modes — hallucination, drift, prompt injection, citation errors are failure modes that don't exist in traditional retrieval. The discipline is recognizing that LLM augmentation isn't free; the value must justify the cost.
The incremental adoption pattern. The most successful production LLM-augmented systems adopt incrementally. They identify one stage where LLM augmentation has the highest leverage — typically reranking or synthesis — deploy it, measure the impact, and only then expand to additional stages. Teams that try to LLM-augment everything at once produce systems that are slow, expensive, and unreliable; teams that augment selectively produce systems that capture most of the value at manageable cost. The discipline mirrors the operational discipline from Volume 6 — small, measured changes beat large untested rollouts.
Chapter 2. The LLM in Each Stage of the Pipeline
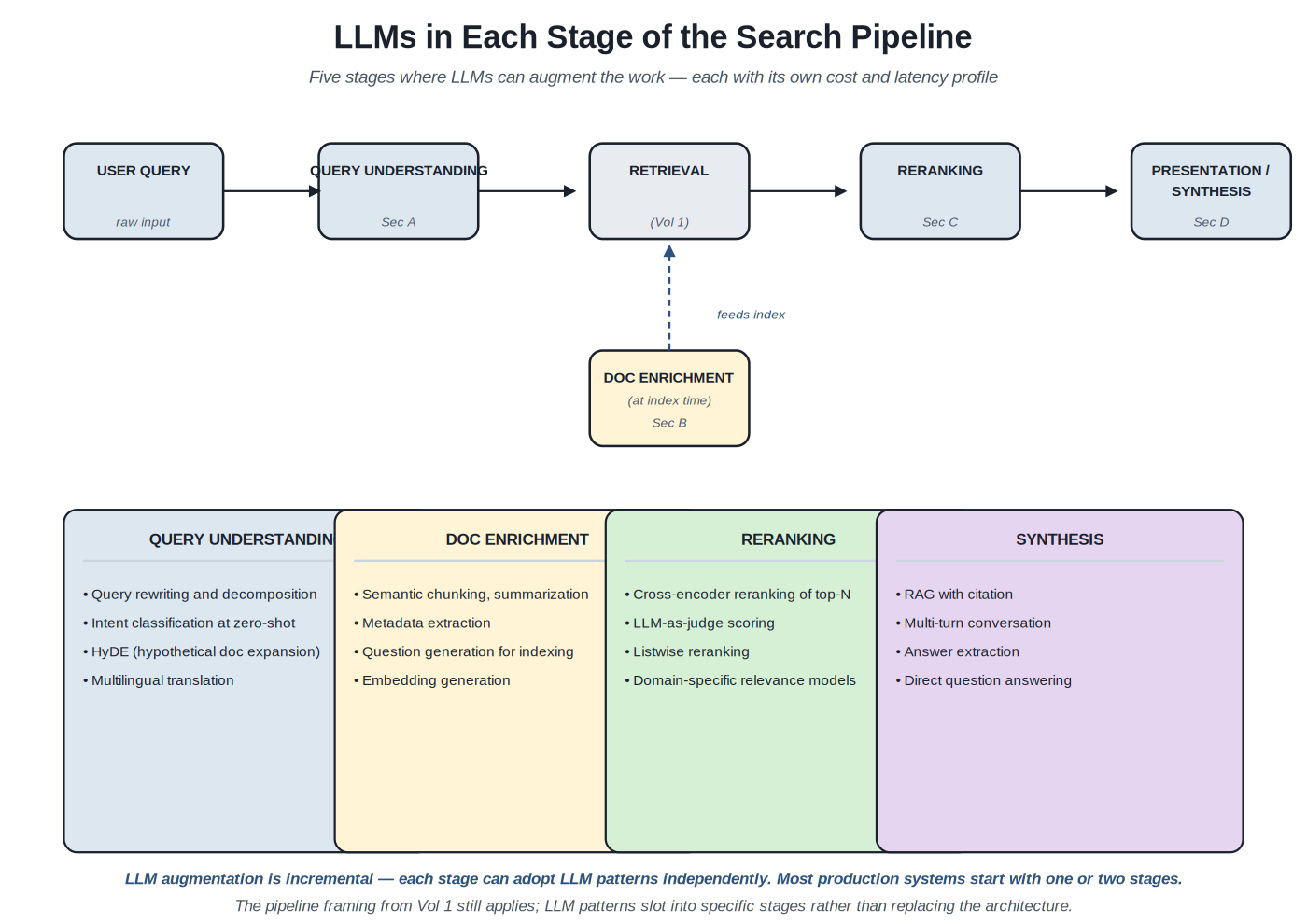
{kind=link}
Five stages where LLMs can augment the work. Each stage has its own cost, latency, and quality profile. LLM augmentation is incremental — each stage can be adopted independently.
Query understanding (Section A). LLMs at this stage rewrite, decompose, expand, or classify the user's query. A query like "what\'s the cheapest flight from SF to NYC in March" might be rewritten to extract structured parameters (origin: SFO; destination: JFK or LGA or EWR; month: March; sort: price ascending). Hypothetical document expansion (HyDE) is a clever pattern where the LLM produces a hypothetical answer to the query, and the system retrieves documents similar to the hypothetical answer rather than to the query itself — often improving recall substantially. Latency at this stage is single-LLM-call (100–500ms); cost is per-query.
Document enrichment (Section B). LLMs at this stage transform documents at index time — not at query time — enriching them with summaries, extracted metadata, semantic chunks, or generated questions that the document answers. The transformation happens once per document; the costs are amortized across all future queries. This is structurally the most efficient place to apply LLMs because the latency budget at index time is loose. A 10-second LLM call to enrich a document is fine if the document gets queried thousands of times; the same call at query time would be unacceptable.
Retrieval (still traditional). The retrieval stage — the actual lookup against the index — typically remains lexical (BM25) or vector (embeddings) or hybrid. LLMs at this stage are too expensive; you can't run an LLM call against every document in the index for every query. The closest pattern is LLM-generated embeddings used in vector search, but the embeddings are generated at index time and at query time once per query, not per (query, doc) pair. The retrieval stage retains the structural properties from Volume 1: fast, cheap, recall-oriented.
Reranking (Section C). LLMs at this stage re-order a small candidate set (top 20–100 from retrieval) by relevance to the query. This is the highest-leverage place for LLM augmentation in many systems. The cost is bounded — you're running LLM calls on dozens of candidates, not millions — and the quality lift is substantial because reranking has direct visible impact on the top results users see. Three variants: cross-encoder models (cheap, fast, batched), LLM-as-judge (high quality, higher cost), listwise LLM (highest quality, highest cost). Most production systems start with cross-encoder rerankers and add LLM-as-judge for harder workloads.
Presentation / synthesis (Section D). LLMs at this stage generate user-facing content — synthesized answers, summaries, conversational responses, citations — from the retrieved documents. This is what most users mean by "AI search"; the LLM-generated answer that appears at the top of results. The pattern is RAG (retrieval-augmented generation). Latency is the highest because the LLM has to read the retrieved context and generate output; cost is the highest per query because the input context is large. The quality lift is also the largest — for informational queries, a good synthesized answer with citations beats a list of links.
Chapter 3. RAG: Retrieval-Augmented Generation
RAG is the canonical pattern for LLM-augmented conversational search. The pattern: retrieve relevant documents from an index, format them as context for an LLM prompt, and have the LLM generate an answer grounded in that context with citations back to the source documents. The pattern emerged through 2022–2024 and consolidated into production practice through 2024–2026.
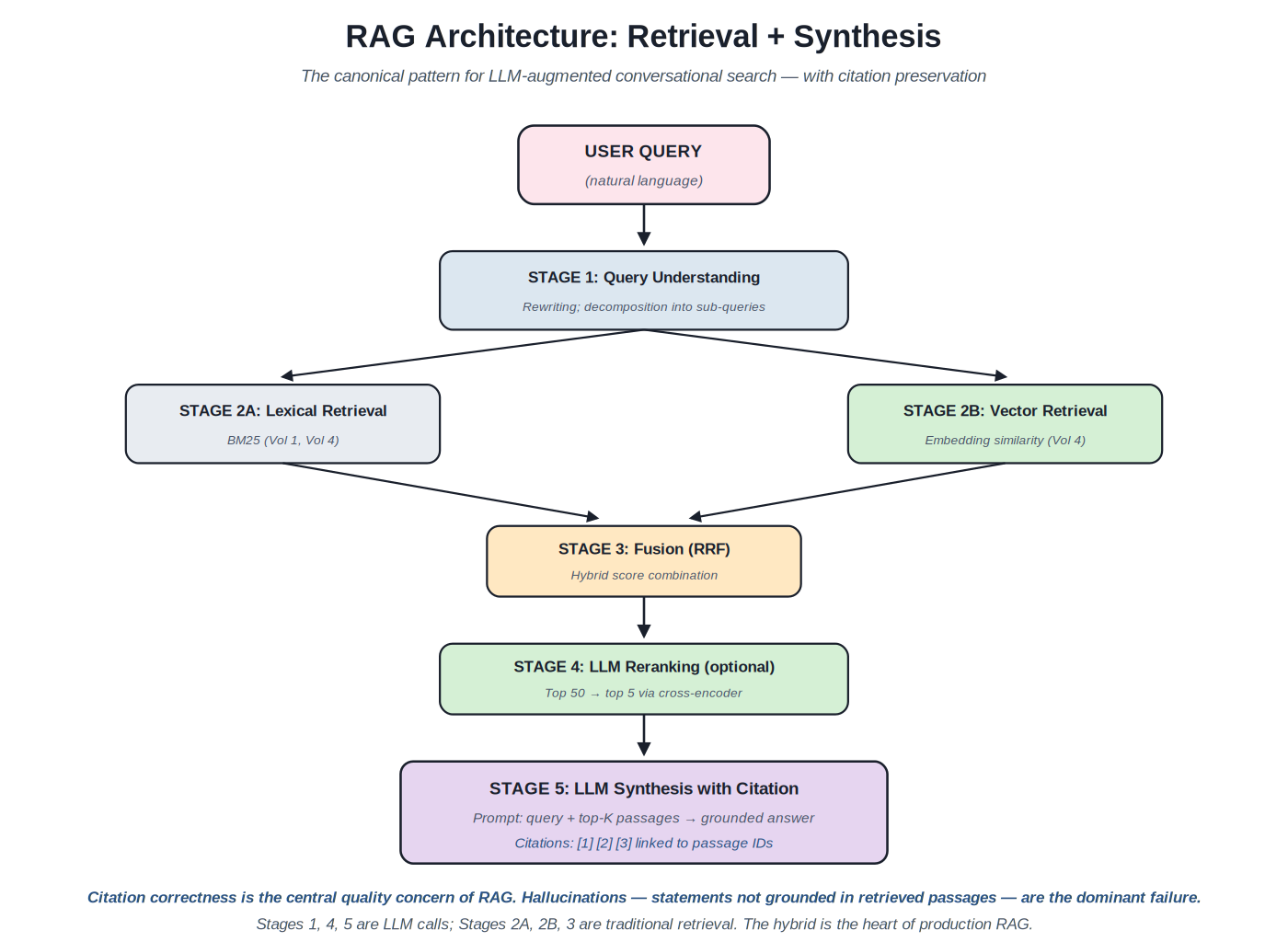
{kind=link}
The canonical RAG pipeline: query understanding → hybrid retrieval → fusion → LLM reranking (optional) → LLM synthesis with citation. Stages 1, 4, 5 are LLM calls; Stages 2-3 are traditional retrieval.
Stage 1: Query understanding. The user's query may need rewriting for retrieval. A conversational query ("what about for kids?" following a previous turn about adult hiking boots) needs context-aware rewriting ("hiking boots for children"). A complex query ("compare BM25 and dense retrieval for code search") might decompose into sub-queries. The LLM call at this stage produces a normalized query (or queries) that the retrieval stage will work with.
Stages 2A and 2B: Hybrid retrieval. Lexical retrieval (BM25) catches exact-term matches; vector retrieval (embedding similarity) catches semantic matches. Most production RAG systems run both in parallel and merge the results. The merging is typically Reciprocal Rank Fusion (RRF) or weighted score combination; both approaches work; RRF is simpler and parameter-free for the merging step.
Stage 3: Fusion. The top results from lexical and vector retrieval are combined into a unified candidate set. The set is typically 20–50 documents; large enough to capture the relevant content, small enough that the next stages can afford to process each document.
Stage 4 (optional): LLM reranking. The candidate set is reranked by an LLM or cross-encoder. This stage adds latency and cost but substantially improves the top-K quality. Many production systems include this stage; some skip it when the retrieval quality is good enough on its own.
Stage 5: LLM synthesis with citation. The top 3–10 documents from reranking are formatted as context in a prompt to the LLM. The prompt instructs the LLM to answer the user's query using only the provided context, and to cite specific documents for each statement. The LLM generates a synthesized answer; the citations are surfaced as clickable references in the UI. This stage produces the user-visible output.
The central quality concern: citation correctness. RAG systems can produce convincing-sounding answers that aren't actually grounded in the retrieved passages. The LLM may invent facts, attribute them to the wrong source, or cite a passage that doesn't actually support the claim. Citation correctness — the property that every statement in the synthesized answer is actually supported by a citable passage — is the central quality metric for RAG. Evaluation patterns for this are covered in Section F.
The conversational extension. Multi-turn RAG — conversational search where the user asks follow-up questions — adds context-handling complexity. The follow-up question may not stand alone ("how much?" needs the prior turn to be meaningful). Production patterns: rewrite the follow-up using context before retrieval; maintain a conversation history in the prompt; selectively forget early turns to control prompt length. Section D covers these patterns in depth.
Chapter 4. Evaluation in the LLM-Augmented World
Volume 5 documented the discipline of search evaluation — metrics, judgment, online evaluation. LLM-augmented search adds new dimensions that Volume 5 didn't cover. Faithfulness, citation correctness, hallucination rate, drift detection — these are concerns specific to LLM-augmented systems that need their own evaluation patterns.
Faithfulness. The property that synthesized output is consistent with the retrieved context. A faithful answer makes no claims beyond what the retrieved passages support. Measuring faithfulness typically uses LLM-as-judge: another LLM call that examines the synthesized answer and the source passages and rates whether each claim in the answer is supported. This is itself an LLM-augmented evaluation pattern (Section F) with its own reliability concerns; calibrated judgment requires careful prompt design and human verification of the judge's reliability.
Citation correctness. The property that each citation points to a passage that actually supports the cited claim. Distinct from faithfulness because citations can be wrong even when the answer is correct (the LLM attributed a true claim to the wrong document). Measuring requires examining each citation explicitly. Section F covers the measurement patterns.
Hallucination rate. The property that the system invents content not supported by any source. Hallucination is the headline failure mode of LLM-augmented search; production systems must measure and minimize it. Patterns: structured prompts that explicitly forbid unsupported claims; verification stages that check each claim against sources; refusal patterns where the LLM is permitted to say "I don't know" when no source supports an answer.
Drift. Model behavior changes over time. The vendor updates the underlying model; behavior shifts subtly; outputs that were good last month are now wrong (or vice versa). Drift detection patterns: maintain a regression test suite of (query, expected output characteristics) pairs; run the suite periodically; alert when outputs change substantially. The discipline mirrors Volume 6 regression detection but for LLM outputs specifically.
Cost and latency as quality dimensions. In traditional search, cost is operational and latency is UX; both are quality concerns but indirectly. In LLM-augmented search, cost and latency directly bound quality — the team can't afford the highest-quality patterns at high query rates, so the deployed quality is bounded by what the team can afford. The trade-off is explicit and ongoing; evaluation patterns must include cost and latency as primary metrics, not just incidental ones.

{kind=link}
Each LLM pattern occupies a different position in the cost-latency-quality space. The discipline is choosing patterns that match your workload's tolerance for each dimension.
Chapter 5. Operating LLM-Augmented Search
Operations for LLM-augmented search differs from operations for traditional search (Volume 6) in several ways. The failure modes are different. The cost structure is different. The monitoring needs are different. The discipline is recognizing where Volume 6's patterns apply unchanged and where they need extension.

{kind=link}
Three new failure-mode categories: hallucination (content not grounded), drift (behavior change over time), operational (cost spikes, rate limits, latency tails).
Cost management. LLM costs scale with query volume in ways that traditional search doesn't. A traditional search system at scale has predictable infrastructure costs; an LLM-augmented system has per-query costs that can spike unexpectedly. Production patterns: explicit budgets per service, with hard cutoffs when exceeded; tiered model selection (Haiku for routine queries, Sonnet for harder, Opus only when needed); aggressive caching of inputs and outputs; degraded modes that disable expensive LLM features under cost pressure. The discipline of running LLM-augmented search includes treating cost as a first-class operational metric.
Latency tail management. LLM call latency has fat tails — p50 might be 500ms but p99 can be 5–10 seconds. Production systems must handle the tail. Patterns: streaming responses to user (the first token arrives quickly even if generation is slow); aggressive timeouts with fallback to non-LLM responses; queue management to smooth traffic spikes; capacity planning for tail latency, not just median. The user-facing latency target is the same as traditional search (sub-second feels fast); the engineering to achieve it differs.
Monitoring and observability. LLM-augmented systems need new monitoring beyond what Volume 6 documented. Token-usage tracking per service and per user. LLM-call latency distributions per stage. Cost attribution per workload. Hallucination rates from sampled output evaluation. Citation correctness from automated checking. Cache hit rates for LLM responses. The observability dashboards extend Volume 6's standard dashboards with LLM-specific metrics.
Fallback patterns. When the LLM augmentation fails (vendor outage, rate limit, timeout, budget exceeded), the system should fall back gracefully to a non-LLM baseline rather than failing visibly. Patterns: synthesis fallback — if LLM synthesis fails, show the top retrieval results as a list (the traditional UX); reranker fallback — if LLM reranker fails, use the post-fusion ranking from retrieval directly; query-understanding fallback — if LLM query rewriting fails, use the raw user query. The fallback paths must be tested regularly; production teams routinely discover that fallback paths have decayed when they're finally needed.
Drift detection and response. As model providers update their models, behavior changes. Production teams need to detect changes and respond. Patterns: regression test suites run on every deployment and weekly thereafter; canary deployments that route a small fraction of traffic to new model versions before full rollout; A/B testing of model upgrades against the previous version; explicit version pinning where the team needs stability over freshness (pin to a specific Claude model version rather than 'claude-latest').
The operational maturity curve. LLM-augmented search at production scale requires substantial operational maturity. Teams that have not yet built the basic operational practice from Volume 6 should not attempt to operate LLM-augmented search; they'll be overwhelmed by failures they can't diagnose. Teams with mature Volume 6 practice can extend it to LLM-augmented search with manageable additional investment. The investment is real but bounded — typically 6–12 months for a team with existing search operational maturity to develop LLM-augmented operational competence.
Part 2 — The Substrates
Eight sections cover the LLM-augmentation patterns. Each section opens with a short essay on what its patterns share. Representative patterns appear in the Fowler-style template with concrete artifacts — prompts, code, configurations — for the central methods.
Sections at a glance
- Section A — LLM-augmented query understanding
- Section B — LLM-augmented document processing
- Section C — LLM-as-reranker
- Section D — Conversational synthesis and RAG
- Section E — Hybrid retrieval patterns
- Section F — LLM-augmented evaluation
- Section G — Operations for LLM-augmented search
- Section H — Discovery and resources
Section A — LLM-augmented query understanding
Where LLMs reshape the query before retrieval ever runs
Query understanding is the highest-leverage early stage — a better query produces better retrieval, and LLMs can shape queries in ways traditional analyzers can\'t. The patterns here cover rewriting, decomposition, expansion, and the HyDE pattern (hypothetical document expansion).
LLM query rewriting with conversation context #
Source: Production methodology at major RAG products (Perplexity, You.com, ChatGPT browse/search); RAG literature 2023–2025
Classification — Pattern for rewriting user queries to be retrieval-ready, with conversation context preserved for multi-turn search.
Transform raw user queries into queries that produce better retrieval, particularly handling pronoun resolution, context dependencies, and the gap between conversational language and indexable terms.
Raw user queries often retrieve poorly. 'How much does it cost' alone has no useful retrieval target; the context of the prior conversation is needed. 'Best for kids' needs the category context (best running shoes? best laptops?) to retrieve usefully. Traditional query analyzers can't fill these gaps because they don't reason about context.
LLMs are well-suited to query rewriting because the task is exactly what they're trained for: take linguistic input, produce linguistic output, using context. The latency cost is acceptable (single LLM call, typically 100–300ms with a small fast model); the quality lift is substantial; the implementation is straightforward.
Input. The user's current message plus the conversation history (or a summary of it). Production patterns: include last 3–5 turns verbatim; longer history summarized; cap total context at a few thousand tokens to control LLM cost.
Prompt. A clear instruction to produce a self-contained query suitable for retrieval. The prompt should specify: produce a single retrieval query, not multiple; preserve user intent precisely; resolve pronouns and references from context; output the query directly without explanation.
Output handling. The LLM returns the rewritten query. Production patterns: strip any wrapping (explanations, quotes) the LLM may add; validate the output isn't empty; fall back to the original query if rewriting fails or produces obviously wrong output.
Multi-query expansion. A variant where the LLM produces multiple queries from a complex input. Useful when the user's question spans multiple sub-topics; each sub-query goes through retrieval independently and results are merged. Production patterns: cap the number of sub-queries (typically 3–5) to control cost; assign each sub-query equal weight unless intent suggests otherwise.
Caching. The same (query, context) pair appearing again should hit cache. Production patterns: cache the rewritten query keyed on a hash of the user query and a few preceding turns; cache lifetime modest (hours) since users' conversational patterns evolve. Even modest cache hit rates substantially reduce cost.
Failure handling. The rewriting LLM may fail (timeout, rate limit, vendor outage). Fallback: use the original query unchanged. The fallback path must be tested regularly; production teams routinely discover their fallback paths have decayed.
Conversational search products where multi-turn queries are common. Workloads where user queries are short or context-dependent ('what about for kids?', 'how much?'). RAG systems where the retrieval quality directly determines the generated answer quality.
Less good fit — single-shot queries where there\'s no conversation context to bring in. E-commerce search where queries are explicit and retrieving the exact terms matters. High query volume systems where the per-query LLM cost is prohibitive (consider caching aggressively or limiting to harder queries).
- Perplexity AI engineering blog posts on conversational query handling
- OpenAI blog posts on ChatGPT search retrieval architecture
- RAG literature: Lewis et al. (2020) original RAG paper; Gao et al. (2024) RAG survey
Code
# Query rewriting with conversation context (Python + Anthropic SDK)
import anthropic
from typing import List, Dict
client = anthropic.Anthropic()
QUERY_REWRITE_PROMPT = """You are a search query rewriter. Given a conversation history and a new user message, produce a single self-contained search query suitable for retrieval.
Rules:
- Produce ONE query, not multiple
- Resolve any pronouns or references from the conversation context
- Preserve the user's intent precisely
- Do not add interpretation beyond what's in the conversation
- Output ONLY the query, no explanation, no quotes
Conversation history (most recent last):
{history}
User's new message: {query}
Rewritten query:"""
def rewrite_query(query: str, history: List[Dict[str, str]]) -> str:
"""
Rewrite a user query for retrieval, using conversation context.
Args:
query: The user's current query
history: List of {role: 'user'|'assistant', content: str} dicts
Returns:
A retrieval-ready query string. Falls back to the original on failure.
"""
if not history:
return query # No context, nothing to rewrite
# Format recent history (last 5 turns)
recent = history[-5:]
formatted = "\n".join(
f"{turn['role']}: {turn['content']}" for turn in recent
)
try:
response = client.messages.create(
model="claude-haiku-4-5-20251001", # cheap, fast
max_tokens=200,
messages=[{
"role": "user",
"content": QUERY_REWRITE_PROMPT.format(
history=formatted, query=query
)
}]
)
rewritten = response.content[0].text.strip()
# Validate: not empty, not too long
if not rewritten or len(rewritten) > 500:
return query
# Strip quotes if LLM added them
rewritten = rewritten.strip('"').strip("'").strip()
return rewritten
except Exception:
# Any failure → fall back to original query
return query
# Example usage:
history = [
{"role": "user", "content": "What are the best running shoes for trail?"},
{"role": "assistant", "content": "Top trail running shoes include the Salomon Sense Ride..."},
{"role": "user", "content": "What about for kids?"},
]
# Without rewriting: "What about for kids?" → useless retrieval
# With rewriting: "best trail running shoes for kids" → strong retrievalSection B — LLM-augmented document processing
Use LLMs at index time, where the latency budget is loose and costs are amortized
Document processing is the structurally most efficient place to apply LLMs. The cost is paid once at index time, amortized across all future queries against that document. Patterns here cover semantic chunking, summarization for indexing, metadata extraction, and question generation.
Semantic chunking and indexed summarization for RAG #
Source: Production RAG methodology; Anthropic, OpenAI, LangChain documentation on document processing; literature 2023–2025
Classification — Pattern for breaking documents into retrieval-appropriate chunks and generating summaries that improve both retrieval recall and synthesis quality.
Prepare documents for retrieval-augmented use by chunking them into semantically coherent pieces and generating summaries that capture each chunk\'s gist, enabling better embedding-based retrieval and clearer LLM synthesis context.
Raw documents don\'t fit neatly into LLM context windows or embedding inputs. A 50-page document can\'t be embedded as one vector; the embedding would average too many concepts. But naive fixed-size chunking (every 500 tokens) breaks semantic boundaries — a paragraph might span chunks, an argument might be split. Both retrieval recall and synthesis context suffer.
LLM-augmented chunking respects semantic boundaries: paragraph breaks, section transitions, logical units. The result is chunks that each cover one coherent topic, with consistent size suitable for embedding and prompt construction.
Step 1: structural parsing. Parse the document\'s structure (headings, paragraphs, lists) using its native format (Markdown, HTML, PDF outline). The structure provides natural chunk boundaries before LLM involvement.
Step 2: chunk sizing. Within each structural unit, apply size limits. Target chunk size depends on the downstream use: 200–500 tokens for fine-grained retrieval; 1000–2000 for synthesis context. Use overlap (50–100 tokens) between adjacent chunks to preserve cross-chunk coherence.
Step 3: semantic chunking when structure is unreliable. For unstructured text (transcripts, scanned OCR, social posts), use an LLM to identify natural break points. The LLM is shown the text and asked where to split it; the output drives chunking. Latency at index time is acceptable for this; quality is substantially better than fixed-size chunking.
Step 4: chunk summarization. For each chunk, generate a 1–2 sentence summary. The summary serves two purposes: it\'s indexed alongside the chunk text for retrieval; it\'s surfaced as part of synthesis context when the chunk is retrieved. Summaries dramatically improve recall on conceptual queries that don\'t share vocabulary with the chunk text.
Step 5: question generation. An optional extension: for each chunk, ask the LLM 'what questions does this chunk answer?' and generate 3–5 likely user questions. Index those questions alongside the chunk. Queries that match the generated questions retrieve the chunk strongly, even when the user\'s wording differs from the document\'s wording.
Step 6: metadata extraction. Extract structured metadata from each chunk — dates, entities, categories, key facts. Store as structured fields for filtering and faceting. This stage transforms unstructured text into hybrid structured-unstructured content that supports much richer queries.
Cost considerations. All of this work happens at index time. For 100,000 documents averaging 10 chunks each, that\'s 1M LLM calls for full enrichment — substantial cost. Production patterns: incremental processing (only re-process changed documents); batch processing during off-peak hours; tiered processing (cheap models for routine documents, expensive models for high-value ones); selective enrichment (summarize only chunks above a length threshold).
Any RAG system over substantial document collections (more than a few thousand documents). Knowledge bases, documentation search, technical reference search. Workloads where retrieval recall on conceptual queries is currently weak.
Less good fit — small document collections where the engineering investment isn\'t justified. Workloads with highly structured documents (database records) that don\'t need chunking. Cost-sensitive deployments where the index-time enrichment cost is prohibitive.
- LangChain and LlamaIndex documentation on document chunking
- Anthropic documentation on prompt engineering for document processing
- RAG literature: chunk-size studies (LlamaIndex 2024 retrieval benchmarks)
Code
# Semantic chunking with LLM-generated summaries (Python)
from typing import List, Dict
import anthropic
client = anthropic.Anthropic()
CHUNK_SUMMARY_PROMPT = """Summarize this passage in 1--2 sentences capturing its key claims. Output only the summary; no preamble.
Passage:
{text}
Summary:"""
QUESTION_GEN_PROMPT = """Generate 3--5 likely questions a user might ask that this passage would answer. Output one question per line; no numbering.
Passage:
{text}
Questions:"""
def enrich_chunk(text: str) -> Dict[str, any]:
"""Generate summary and synthetic questions for a chunk.
Returns dict with: text, summary, questions (list).
Falls back to empty enrichments on failure.
"""
enriched = {"text": text, "summary": "", "questions": []}
# Generate summary
try:
resp = client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=150,
messages=[{"role": "user", "content": CHUNK_SUMMARY_PROMPT.format(text=text)}]
)
enriched["summary"] = resp.content[0].text.strip()
except Exception:
pass # Empty summary on failure
# Generate synthetic questions
try:
resp = client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=300,
messages=[{"role": "user", "content": QUESTION_GEN_PROMPT.format(text=text)}]
)
questions = [
q.strip("- \u2022 \t").strip()
for q in resp.content[0].text.strip().split("\n")
if q.strip()
]
enriched["questions"] = questions[:5] # cap at 5
except Exception:
pass
return enriched
def build_index_document(chunk_text: str) -> Dict:
"""Build a complete indexable document from a chunk.
The result is indexed with multiple fields:
- text: the chunk text itself (BM25 + embedding)
- summary: the generated summary (BM25 + embedding boost)
- questions: synthetic questions (BM25, treated as queries this chunk answers)
Production retrieval queries the chunk via any of these fields,
substantially improving recall on conceptual queries.
"""
enriched = enrich_chunk(chunk_text)
return {
"text": enriched["text"],
"summary": enriched["summary"],
"questions": enriched["questions"],
# Plus: embedding(text + summary), structured metadata, etc.
}Section C — LLM-as-reranker
The highest-leverage place for LLM augmentation
Reranking a small candidate set (top 50–100 from broad retrieval) is where LLMs add the most value per dollar. The cost is bounded because the candidate set is small; the quality lift is direct because reranking affects what users see first.
Two-stage retrieval with cross-encoder reranking #
Source: Production RAG methodology; Cohere Rerank documentation; sentence-transformers library; literature on cross-encoders 2019–2025
Classification — Pattern for adding semantic reranking on top of traditional retrieval, using cross-encoder models that score (query, document) pairs.
Lift retrieval quality by re-scoring the top-N candidates from cheap retrieval using a semantic model that\'s too expensive to run on every document but cheap enough for the candidate set.
Traditional retrieval (BM25, vector search) is fast and recall-oriented. It returns reasonable candidates but the top-K ordering is often wrong — a relevant document appears at position 15, a less-relevant one at position 2. Users see only the top 5–10; relevant documents below that effectively don\'t exist.
Cross-encoder models score (query, document) pairs jointly, considering full interaction between query terms and document content. They\'re substantially more accurate than retrieval scores but too expensive to apply to millions of documents. The two-stage pattern — cheap retrieval first, expensive reranking on the top-N — captures the best of both.
Stage 1: broad retrieval. Run lexical and/or vector retrieval to produce top 50–200 candidates. The recall target at this stage is high ('is the right answer in the top 200?'); ordering within the set matters less because reranking will reorder.
Stage 2: cross-encoder rerank. Run the cross-encoder model on each (query, candidate) pair. The model outputs a relevance score; sort candidates by score; return the top K (typically 5–10) as the final ranked list.
Cross-encoder model options. Three production paths: open-source pre-trained models (sentence-transformers/ms-marco-MiniLM, BAAI/bge-reranker, mixedbread.ai's mxbai-rerank). Hosted reranker APIs (Cohere Rerank, Voyage AI rerank, Jina rerank). LLM-as-judge with an off-the-shelf LLM (Claude, GPT) prompted to score relevance. Each option has different latency, cost, and quality characteristics.
Latency budget. Reranking a candidate set of 50 takes ~500ms with most cross-encoder models (batched on GPU) or via hosted APIs. This adds to the overall query latency. Production patterns: parallel retrieval and reranking pipeline; result streaming where the user sees initial results while reranking completes; aggressive caching of (query, top-50 candidate IDs) results.
Cost considerations. Per-query cost depends on model and provider. Self-hosted cross-encoders are cheapest after infrastructure amortization; hosted APIs charge per (query, doc) pair; LLM-as-judge is the most expensive per pair. For 1M queries/month against 50-document candidate sets, costs range from $50/month (self-hosted) to $5,000/month (LLM-as-judge with Sonnet-class model).
Quality measurement. Reranking improvement is measured in NDCG@K, MRR, or click-based proxies. Production patterns: A/B test the reranker against the baseline (no reranking); measure both quality and downstream metrics (click-through rate, conversion); maintain a regression suite of (query, expected top result) pairs that catches reranker regressions.
Failure handling. If the reranker fails (timeout, vendor outage, model error), fall back to the post-retrieval ranking unchanged. The fallback degrades quality but preserves availability. Production teams should test the fallback path regularly.
Almost any production retrieval system benefits from reranking. The investment is moderate (cross-encoder models are well-documented; hosted APIs are turnkey); the quality lift is substantial. The most common pattern is to start with a hosted reranker (Cohere or Voyage) for fast adoption, then evaluate self-hosting once the value is proven.
Less good fit — latency-critical systems where the additional 500ms is unacceptable. Pure-keyword search where lexical match is the primary signal. Very small candidate sets where the existing ordering is fine (e.g., navigational queries with a single expected result).
- Cohere Rerank API documentation (docs.cohere.com)
- sentence-transformers library documentation
- Anthropic documentation on LLM-as-judge patterns
- MTEB (Massive Text Embedding Benchmark) leaderboards for reranker model selection
Code
# Two-stage retrieval with hosted reranker (Python)
from typing import List, Dict
import cohere
co = cohere.Client()
def hybrid_retrieve(query: str, k: int = 50) -> List[Dict]:
"""Stage 1: broad retrieval. Returns top-K candidates with text + ID.
Implementation depends on your backend (Elasticsearch, vector DB, etc).
This is a placeholder showing the expected return shape.
"""
# Run lexical (BM25) and vector retrieval in parallel
# Merge via RRF or weighted score
# Return top-K
return [
{"id": "doc_42", "text": "...", "score": 0.87},
{"id": "doc_88", "text": "...", "score": 0.81},
# ... up to k
]
def rerank(query: str, candidates: List[Dict], top_k: int = 10) -> List[Dict]:
"""Stage 2: cross-encoder rerank. Re-orders candidates by semantic relevance.
Falls back to the input ordering on failure.
"""
if not candidates:
return []
try:
response = co.rerank(
model="rerank-english-v3.0",
query=query,
documents=[c["text"] for c in candidates],
top_n=top_k,
return_documents=False,
)
# response.results is sorted by relevance, with .index pointing to input position
reranked = []
for r in response.results:
original = candidates[r.index]
reranked.append({
**original,
"rerank_score": r.relevance_score,
})
return reranked
except Exception:
# Fall back to retrieval ordering
return candidates[:top_k]
def search(query: str, top_k: int = 10) -> List[Dict]:
"""End-to-end search: retrieve broadly, rerank narrowly."""
candidates = hybrid_retrieve(query, k=50)
return rerank(query, candidates, top_k=top_k)Section D — Conversational synthesis and RAG
The user-facing output stage: generate answers grounded in retrieved passages
RAG (retrieval-augmented generation) is the canonical pattern for LLM-generated answers grounded in retrieved sources. The patterns here cover the prompt structure, citation handling, and the discipline of producing faithful, citable outputs.
RAG synthesis with grounded citation #
Source: Production methodology at major RAG products (Perplexity, ChatGPT, Claude); Anthropic, OpenAI citation documentation; RAG literature 2024–2026
Classification — Pattern for producing user-facing synthesized answers from retrieved passages with verifiable citations to source documents.
Generate natural-language answers that satisfy informational queries directly while preserving the user\'s ability to verify each claim against source passages through cited references.
Generated answers without citations are unverifiable; users can\'t tell which claims are supported and which the LLM invented. Citations restore verifiability but create their own quality concerns: citation drift (citation points to wrong passage), citation invention (citation refers to a non-existent passage), partial citation (claim supported only partially by the cited passage).
Producing reliable RAG output is a discipline involving prompt design, output parsing, and verification. The patterns documented here represent the production consensus through 2024–2026.
Prompt structure. The system prompt instructs the LLM to: answer using only the provided passages; cite each claim with the source passage ID; refuse to answer if the passages don\'t support a confident response. The user message contains the query and the formatted passages. Each passage has a clear ID (P1, P2, etc.) that the LLM uses for citation.
Passage formatting. Each passage is formatted with a clear ID, the passage text, and optionally the source document title/URL. Production patterns: place passages between explicit delimiters (XML tags work well: <passage id=\"P1\">...</passage>); order passages by retrieval relevance; cap passage count at 5–10 to keep prompts focused and costs bounded.
Output structure. The LLM produces an answer with inline citations like [P1] [P2]. Production parsers extract these citation markers and link them to the passage IDs. UI then renders citations as clickable references to source documents.
Faithfulness verification. After generation, a verification step checks that each cited claim is actually supported by the cited passage. Production patterns: pattern match cited claims against passages; LLM-based verification (separate LLM call to check each claim); human review for high-stakes domains. The verification stage catches hallucinations that the generation stage missed.
Refusal patterns. The LLM should refuse to answer when passages don\'t support a confident response. Production prompts include explicit instructions: 'If the passages don\'t contain enough information to answer, say so directly.' The refusal pattern is critical for trustworthiness; without it, the LLM tends to fabricate answers when context is insufficient.
Conversation context. Multi-turn RAG maintains conversation history. Production patterns: include last N turns verbatim in the prompt; summarize older turns; query rewriting (Section A) makes the current query self-contained for retrieval; synthesis uses both the rewritten query and the original conversational query so the response feels conversationally appropriate.
Streaming responses. RAG generation has substantial latency (1–3 seconds for typical answers). Streaming the response token-by-token makes the latency more tolerable; users see content appearing immediately. Production patterns: stream the synthesis output to the UI; render citations as they appear; allow user to interrupt or scroll while generation continues.
Cost considerations. Each RAG query has a non-trivial cost. Input tokens (the formatted passages) often dominate — 5 passages of 500 tokens each plus the system prompt is 3000+ input tokens. Output tokens are smaller (typical answers are 200–500 tokens). Production patterns: cache frequent (query, passage-set) combinations; tier models (Haiku for routine queries, Sonnet for harder, Opus for the highest-stakes); enforce per-user or per-session cost budgets.
Informational and analytical query workloads where users want answers, not links. Customer support and knowledge-base search where direct answers reduce support load. Research and analysis tools where synthesis of multiple sources is the value proposition.
Less good fit — navigational queries ('Nike homepage') where users want links not essays. Transactional queries ('buy running shoes') where product listings are the right output. High-stakes domains (medical, legal, financial advice) where hallucination risk is unacceptable without robust verification.
- Anthropic documentation on RAG patterns with Claude
- OpenAI cookbook on RAG implementation
- Perplexity AI engineering blog posts on citation handling
- RAG literature: Gao et al. (2024) survey; Lewis et al. (2020) original RAG paper
Code
# RAG synthesis with grounded citation (Python + Anthropic SDK)
from typing import List, Dict
import anthropic
import re
client = anthropic.Anthropic()
RAG_SYSTEM_PROMPT = """You are a search assistant. Answer the user's question using ONLY the provided passages.
Rules:
- Cite each claim with the passage ID in brackets, e.g. [P1] [P2]
- If the passages don't contain enough information for a confident answer, say so directly and don't fabricate
- Keep answers concise: 2--4 sentences for simple questions, 1--2 paragraphs for complex ones
- Don't invent citations; only cite passages that actually appear in the input"""
def format_passages(passages: List[Dict]) -> str:
"""Format retrieved passages for inclusion in the prompt."""
return "\n\n".join(
f'<passage id="P{i+1}">\n{p["text"]}\n</passage>'
for i, p in enumerate(passages)
)
def synthesize(query: str, passages: List[Dict]) -> Dict:
"""Generate a RAG answer with citations.
Returns dict with: answer, citations (list of passage IDs cited).
"""
user_message = f"""Passages:
{format_passages(passages)}
Question: {query}
Answer (with citations):"""
try:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1000,
system=RAG_SYSTEM_PROMPT,
messages=[{"role": "user", "content": user_message}]
)
answer = response.content[0].text
# Extract citation IDs (e.g., [P1], [P2])
cited_ids = set(re.findall(r"\[P(\d+)\]", answer))
# Map back to source documents
cited = []
for cid in cited_ids:
idx = int(cid) - 1
if 0 <= idx < len(passages):
cited.append({
"passage_id": f"P{cid}",
"source": passages[idx].get("source_id", ""),
"text": passages[idx]["text"],
})
return {
"answer": answer,
"citations": cited,
}
except Exception as e:
return {
"answer": "I'm unable to generate an answer right now. Here are the relevant passages I found:",
"citations": [],
"error": str(e),
"fallback_passages": passages, # UI falls back to passage list
}Section E — Hybrid retrieval patterns
How LLM augmentation interacts with traditional lexical and vector retrieval
Modern production retrieval is hybrid — lexical (BM25) plus vector plus, increasingly, LLM augmentation. The patterns here cover how these techniques combine, when to use which, and how fusion methods like RRF work in practice.
Hybrid retrieval with Reciprocal Rank Fusion (RRF) #
Source: Production methodology; Cormack et al. (2009) original RRF paper; current platform documentation (Elasticsearch, Vespa, etc.)
Classification — Pattern for combining results from multiple retrieval methods (lexical + vector + LLM-derived signals) into a single ranked list without needing per-method score calibration.
Combine the recall of lexical matching, the semantic understanding of vector search, and the optional LLM-augmented signals into a unified retrieval result that's better than any single method alone.
Lexical retrieval (BM25) is strong on exact-term matches, weak on synonyms and paraphrasing. Vector retrieval is strong on semantic matches, weak on exact terms (especially proper nouns, product SKUs, identifiers). Each method retrieves documents the other misses. A hybrid approach gets both.
Combining results requires a fusion method. Raw score combination is brittle — BM25 and vector scores are on different scales; weighted combinations require careful calibration that changes when models update. RRF avoids this by using only rank positions, not scores. The result is a robust fusion method that requires zero tuning.
Run each retrieval method independently. Lexical (BM25 against tokenized index) and vector (cosine similarity against embedding index) execute in parallel; each returns its own top-K ranked list. Production patterns: parallelize the calls; cap K at 50–100 per method; ensure consistent document IDs so the same document is recognized across methods.
Compute RRF score per document. For each document, the RRF score is the sum across methods of 1/(k + rank_in_that_method), where rank is the 1-indexed position in that method's ranked list, and k is a constant (typically 60). Documents that rank high in any method get high RRF scores; documents that rank moderately in multiple methods can outscore documents that rank top in only one.
Sort by RRF score. The unified ranked list is just the documents sorted by descending RRF score. Truncate to your target top-K (typically 20–50 for downstream reranking, 5–10 for direct presentation).
Per-method weighting (optional). If you want one method to count more than another, multiply each method's contribution by a weight. Production practice: start with equal weighting; only deviate when measurement justifies it. Often the equal-weight RRF is good enough that tuning weights doesn't pay off.
Adding LLM-derived signals. Two patterns. First, treat LLM query rewriting as a separate retrieval branch: rewrite the query with an LLM, run retrieval on the rewritten query, add the result as another input to RRF. Second, treat LLM reranking (Section C) as a post-fusion stage rather than a fusion input: RRF combines lexical + vector; then the reranker re-orders the unified top-K. Both patterns work; the choice depends on where the LLM cost is most easily absorbed.
Validation. RRF is well-studied; production teams should still validate it against their workload. Maintain offline measurement (NDCG, MRR on judged sets) comparing RRF against single-method baselines and against weighted combinations. Online A/B testing for production rollout. The validation effort is modest because RRF has few tuning parameters.
Almost any modern production retrieval. The combination of lexical + vector + RRF is the default starting point through 2024–2026; teams that haven't adopted it are leaving recall on the table. The implementation is straightforward; the quality lift is consistent across workloads.
Less good fit — workloads with extreme latency budgets where running two parallel retrieval methods is too expensive. Workloads where one method is dramatically better than the other (rare in practice).
- Cormack, Clarke, Buettcher (2009) 'Reciprocal Rank Fusion outperforms Condorcet and individual rank learning methods'
- Elasticsearch RRF documentation
- Vespa documentation on hybrid retrieval
- Anthropic documentation on hybrid search for RAG
Code
# Reciprocal Rank Fusion (RRF) implementation (Python)
from typing import List, Dict, Iterable
from collections import defaultdict
def rrf_fuse(
ranked_lists: Iterable[List[Dict]],
k: int = 60,
weights: List[float] = None,
id_field: str = "id",
) -> List[Dict]:
"""Fuse multiple ranked lists using Reciprocal Rank Fusion.
Args:
ranked_lists: Iterable of ranked lists. Each list is sorted by relevance descending.
Each item must have an `id` field (or whatever id_field specifies).
k: RRF constant (default 60). Higher k softens the rank influence.
weights: Optional per-method weights. Default: equal weighting.
id_field: The field on each item that uniquely identifies a document.
Returns:
Unified ranked list sorted by descending RRF score, with `rrf_score` added.
"""
ranked_lists = list(ranked_lists)
if weights is None:
weights = [1.0] * len(ranked_lists)
assert len(weights) == len(ranked_lists)
# Accumulate scores per document
scores = defaultdict(float)
docs_by_id = {}
for weight, ranked_list in zip(weights, ranked_lists):
for rank, doc in enumerate(ranked_list, start=1):
doc_id = doc[id_field]
scores[doc_id] += weight * (1.0 / (k + rank))
# Keep the first occurrence's full doc (preserves text, metadata)
if doc_id not in docs_by_id:
docs_by_id[doc_id] = doc
# Build unified ranked list
fused = []
for doc_id, score in sorted(scores.items(), key=lambda x: -x[1]):
doc = dict(docs_by_id[doc_id])
doc["rrf_score"] = score
fused.append(doc)
return fused
# Example usage:
lexical_results = [
{"id": "doc_42", "text": "...", "bm25": 12.4},
{"id": "doc_88", "text": "...", "bm25": 11.1},
{"id": "doc_15", "text": "...", "bm25": 9.8},
]
vector_results = [
{"id": "doc_88", "text": "...", "cosine": 0.92},
{"id": "doc_71", "text": "...", "cosine": 0.89},
{"id": "doc_42", "text": "...", "cosine": 0.84},
]
# Equal-weighted fusion
fused = rrf_fuse([lexical_results, vector_results])
# Top results: doc_42 and doc_88 (both rank high in both methods) win over
# doc_71 (only appears in vector) and doc_15 (only appears in lexical)Section F — LLM-augmented evaluation
How to measure quality when the system has LLM stages
Volume 5 documented the discipline of search evaluation. LLM-augmented systems need additional patterns — faithfulness, citation correctness, hallucination rate, drift detection. The patterns here document those extensions.
LLM-as-judge for relevance and faithfulness evaluation #
Source: Production methodology; literature on LLM-as-judge (Zheng et al. 2023 MT-Bench, RAGAS, TruLens); current vendor documentation
Classification — Pattern for using a separate LLM to evaluate the quality of LLM-augmented search outputs, at scales that would be impractical for human judgment.
Provide judgment signal at scale by using an LLM to assess relevance of retrieved passages, faithfulness of synthesized answers, and citation correctness — with appropriate calibration against human judgment as ground truth.
LLM-augmented systems need evaluation beyond what human judgment can provide at scale. Human judgment is high-quality but expensive and slow — maybe 50 judgments per hour per judge. LLM-augmented systems may need thousands of judgments per day for regression detection, A/B testing, drift detection. Human judgment alone can't keep up.
LLM-as-judge fills the gap: a separate LLM call examines a (query, output) pair and rates quality. Calibrated against human judgment on a sample, LLM-as-judge produces useful evaluation signal at scale. The patterns here document the calibration discipline that makes LLM-as-judge reliable.
Define the judgment task precisely. 'Relevance' is too vague; the LLM judge needs a clear specification. Production patterns: write a judging rubric that defines specific levels (e.g., 3=highly relevant, 2=partially relevant, 1=marginally relevant, 0=irrelevant); include examples of each level; specify edge cases. The rubric is itself a versioned artifact that improves over time.
Choose the judge model. Stronger models produce more reliable judgments but cost more. Production patterns: use a model class above what generates the output (if generation is Sonnet, judging is Opus or above); use the same vendor or a different one based on independence preferences; pin to a specific version for stability.
Prompt design. The judge prompt should: provide the rubric clearly; show the query and the output; specify the output format (a single integer score, or structured JSON). Production patterns: ask for explanation before score (improves accuracy); use few-shot examples in the prompt; require exact-format output for parsing.
Calibrate against human judgment. Run a sample of (query, output) pairs through both human judges and the LLM judge. Measure agreement: percentage agreement, Cohen's kappa, correlation with human scores. Production patterns: calibrate on at least 100–500 pairs; recalibrate periodically as models update; pin judge model version once calibrated.
Run at scale. With the calibrated judge, evaluate the production system continuously: regression suite of (query, expected quality) pairs run on every deployment; A/B test arms judged automatically; drift detection by tracking judge scores over time.
Faithfulness-specific patterns. For RAG outputs, faithfulness judging examines each claim in the output against the source passages. Production patterns: extract claims from the output (with another LLM call if needed); for each claim, judge whether the passages support it; aggregate to a faithfulness score per output. RAGAS and TruLens are open-source frameworks implementing this pattern.
Citation correctness specific patterns. Examine each citation in the output: does the cited passage actually support the cited claim? Production patterns: parse out the citation markers and the claims they reference; for each (claim, cited passage) pair, judge whether the passage supports the claim; aggregate to a citation correctness score.
Avoiding judge bias. LLM judges have known biases: positional bias (preferring earlier candidates), length bias (preferring longer outputs), self-preference bias (preferring outputs from the same model family). Production patterns: randomize position in pairwise comparisons; control for length when judging multiple candidates; use a different model family for the judge than for generation.
Production LLM-augmented systems where ongoing quality monitoring at scale is needed. Regression suites for LLM-augmented features. A/B testing of LLM-augmented variants. Drift detection across model updates.
Less good fit — small systems where human judgment is sufficient. Very high-stakes domains where automated judgment isn't trusted enough (medical, legal). Workloads where the judge model itself is uncalibrated.
- Zheng et al. (2023) 'Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena'
- RAGAS framework documentation (github.com/explodinggradients/ragas)
- TruLens documentation (trulens.org)
- Anthropic documentation on LLM-as-judge patterns
Section G — Operations for LLM-augmented search
Running it in production: cost, latency, drift, failure
Volume 6 documented operations for traditional search. LLM-augmented search adds operational concerns the original didn\'t cover: cost management, latency tail handling, drift detection, fallback patterns.
Operational patterns for production LLM-augmented search #
Source: Production operational methodology at LLM-augmented search products; vendor operational documentation (Anthropic, OpenAI, Cohere); literature 2024–2026
Classification — Patterns for running LLM-augmented search reliably at scale, including cost control, latency management, monitoring, and graceful failure.
Extend traditional search operational practice (Vol 6) to handle the new operational concerns LLM augmentation introduces: variable per-query cost, latency tails, drift, vendor dependencies.
LLM-augmented search has operational characteristics traditional search doesn't. Per-query cost varies with prompt length and output length. Latency p99 can be 5–10x p50. The system depends on a vendor that may have outages, rate limits, or unexpected behavior changes. Cost can spike unexpectedly under load. The operational discipline must handle all of this.
Cost monitoring and budgets. Track LLM cost per service, per user, per session, per query class. Set explicit budgets at multiple levels (per-day, per-user, per-feature) with alerting when approaching limits and hard cutoffs when exceeded. Production patterns: tag every LLM call with attribution metadata (service, user, query type); aggregate in real-time; expose dashboards by attribution dimension; alert on anomalies (sudden spend increase).
Tiered model selection. Match model class to query difficulty. Production patterns: classify queries by difficulty (cheap LLM call, heuristic, or based on user/context); route easy queries to cheap models (Haiku-class) and hard queries to expensive models (Sonnet, Opus). Even simple tiering can reduce cost 5–10x with modest quality impact.
Caching at multiple levels. LLM input caching (for prompts that share long prefixes); LLM output caching (for repeated (query, context) inputs); embedding caching (for repeated embedding generation calls). Anthropic and OpenAI both offer prompt caching with substantial cost savings for prefix reuse. Production patterns: design prompts with stable prefixes (system prompt + few-shot examples) followed by variable user input; cache the prefix; cost savings often 50–80% on cached calls.
Latency tail management. p99 LLM latency can be much worse than p50. Production patterns: streaming responses (user sees first tokens quickly even if full generation is slow); per-call timeouts with fallback paths; circuit breakers that disable LLM stages temporarily under sustained latency pressure; capacity planning around p99, not p50.
Rate limit handling. Vendor APIs have rate limits (RPM, TPM). Production patterns: track current rate against limits; queue requests when approaching limit; implement backoff and retry with jitter; have alternative providers configured for failover. Production teams routinely discover their primary vendor at full capacity during traffic spikes; multi-vendor configuration provides resilience.
Drift detection. Vendor model updates can change behavior. Production patterns: pin to specific model versions (not 'latest'); run regression suite on every deployment; monitor key quality metrics over time (sudden changes indicate drift); maintain canary deployments that test new model versions on small fractions of traffic before full migration.
Fallback patterns. When LLM stages fail, gracefully degrade. Production patterns: synthesis fallback (show retrieval results as list); reranker fallback (use post-fusion ranking unchanged); query rewriting fallback (use raw query); have these fallback paths tested regularly to ensure they still work. Production teams routinely discover decayed fallback paths only when they're needed.
Vendor risk management. LLM-augmented systems depend on a small number of vendor APIs. Production patterns: multi-vendor configuration (failover to alternative provider); contractual SLAs for high-availability deployments; cost forecasting that accounts for vendor price changes; periodic re-evaluation of vendor choices as the market evolves.
Incident response for LLM-specific failures. Different from traditional incidents. Patterns: runbook for hallucination spikes (often indicates prompt or context degradation); runbook for cost anomalies (usually a prompt change or unexpected user behavior); runbook for vendor outages (failover steps, user-facing messaging); post-incident reviews that examine LLM-specific contributing factors (prompt changes, model version changes, context changes).
Any production LLM-augmented search at non-trivial scale. The operational discipline is roughly proportional to scale; small experiments need light operations, production systems serving millions of queries need full operational practice.
Less good fit — internal-only systems where reliability requirements are loose. Prototype systems where the operational investment isn't justified yet. The discipline scales with the system's production importance.
- Anthropic documentation on prompt caching and operational patterns
- OpenAI documentation on rate limits and operational patterns
- LangSmith and LangFuse documentation on LLM observability
- Volume 6 of this series for the foundation operational discipline
Section H — Discovery and resources
Where to track the LLM-augmented search field as it evolves
The field is evolving rapidly. The resources here are the most active sources for staying current as patterns mature, models improve, and tools consolidate.
Resources for tracking LLM-augmented search #
Source: Multiple practitioner, academic, and vendor sources
Classification — Sources for staying current on LLM-augmented search practice as the field evolves.
Provide pointers to the active sources of LLM-augmented search knowledge across research, practitioner writing, vendor documentation, and tooling.
The field changes monthly. Patterns that were state-of-the-art in mid-2023 are routine by 2025; patterns that emerge in 2025 will be standard by 2026. Practitioners need ongoing sources rather than fixed reference material.
Vendor documentation. Anthropic's Claude documentation, OpenAI's cookbook, Cohere's docs, Voyage AI's docs — each vendor publishes substantial implementation guidance, pattern documentation, and cookbooks. Reading periodically (every 3–6 months) keeps the mental model current.
Practitioner writing. The most active sources of pattern documentation. Notable publishers: Hamel Husain (consultant blog); Eugene Yan (LLM-applied patterns); Chip Huyen (ML system design); Simon Willison (LLM blog, daily updates); Vicki Boykis (ML newsletter); Jason Liu (Instructor library author, structured-output patterns). The aggregate publication volume is substantial; following 5–10 high-quality voices is the production approach.
Open-source frameworks. LangChain, LlamaIndex are the dominant orchestration frameworks; their documentation and example galleries surface many patterns. Haystack (the framework, distinct from the conference), Semantic Kernel from Microsoft are alternatives. Tracking these projects\' release notes reveals emerging patterns.
Evaluation tools. RAGAS, TruLens, DeepEval, Phoenix from Arize — each is an active project with substantial documentation on evaluation patterns. Adopting one as the evaluation framework is often more efficient than building from scratch.
Research venues. arXiv cs.CL and cs.IR sections have the freshest research. Conferences: ACL, EMNLP, NeurIPS, ICLR, SIGIR, RecSys. The research-to-production lag is typically 6–18 months — papers from late 2024 are becoming production patterns through 2026.
Communities. Latent Space podcast (LLM-applied focus); Last Week in AI newsletter; r/LocalLLaMA (self-hosted LLM community); various Discord servers (LangChain, LlamaIndex, individual model providers). Communities surface real production issues before they reach formal documentation.
Anthropic-specific. For teams using Claude, Anthropic's applied team publishes patterns regularly: Claude Cookbook (github.com/anthropics/anthropic-cookbook), Anthropic documentation on Claude features, Anthropic blog posts on agent and RAG patterns.
Emerging areas through 2026–2027. Multimodal RAG (image + text + audio in unified retrieval); agentic retrieval (LLM-driven multi-step search); structured-output retrieval (function-calling-driven query planning); long-context vs RAG trade-offs (as context windows grow, when is RAG still better?); LLM-specific evaluation tooling; cost optimization at scale.
Search engineers building LLM-augmented features. Consultants advising clients on LLM-augmented search. Engineering managers planning roadmaps in this space. Continuous education as the field evolves.
Alternatives — deep specialization in one platform's tooling for teams with focused commitments. Internal documentation for teams that have developed mature in-house patterns.
- Anthropic Claude documentation (docs.anthropic.com)
- OpenAI Cookbook (cookbook.openai.com)
- LangChain documentation (python.langchain.com)
- LlamaIndex documentation (docs.llamaindex.ai)
- RAGAS framework (github.com/explodinggradients/ragas)
- Hamel Husain blog (hamel.dev)
- Eugene Yan blog (eugeneyan.com)
- Simon Willison blog (simonwillison.net)
- arXiv cs.CL and cs.IR daily listings
Appendix A — Pattern Reference Table
Cross-reference of the LLM-augmented patterns covered in this volume.
| Pattern | Provides | Best fit for | Section |
|---|---|---|---|
| LLM query rewriting | Self-contained queries with context | Conversational search, RAG | Section A |
| HyDE (hypothetical doc) | Retrieve via generated answer | Conceptual queries; broad recall | Section A |
| Semantic chunking | Coherent retrieval units | RAG over documents | Section B |
| Index-time summarization | Better recall on conceptual queries | Knowledge bases; documentation | Section B |
| Cross-encoder reranker | Better top-K ordering | Most production retrieval | Section C |
| LLM-as-judge reranker | Highest reranking quality | High-stakes; harder workloads | Section C |
| RAG with citation | Direct answers with verification | Informational; knowledge bases | Section D |
| Hybrid retrieval with RRF | Recall from lexical + vector | Most modern production retrieval | Section E |
| LLM-as-judge evaluation | Quality signal at scale | Regression, A/B test, drift | Section F |
| Tiered model selection | Cost control | Cost-sensitive production | Section G |
Appendix B — The Nine-Volume Series
This catalog is Volume 9 of the Search Engineering Series. The complete series:
- Volume 1 — The Search Patterns Catalog — query-time architectural patterns.
- Volume 2 — The Query Understanding Catalog — structured query signals.
- Volume 3 — The Indexing and Document Engineering Catalog.
- Volume 4 — The Ranking and Relevance Catalog.
- Volume 5 — The Search Evaluation Catalog.
- Volume 6 — The Search Operations Catalog.
- Volume 7 — The Search UX Patterns Catalog.
- Volume 8 — The Search Platforms Survey.
- Volume 9 — The LLM-Augmented Search Catalog (this volume, optional).
Approximately 500 pages of production search engineering reference across the disciplines, operations, UX, platforms, and the LLM-augmented overlay.
Appendix C — Volume 9\'s Structural Position
Volume 9 occupies a structurally different position than Volumes 1–8 — explicitly marked optional in the series. The position deserves direct discussion.
Why optional. The eight-volume foundation is complete without Volume 9. Production search systems can be built, operated, and improved entirely with the patterns from Volumes 1–8. Many production deployments through 2026 don't use LLM augmentation at all, or use it only in limited ways. The discipline of production search engineering doesn't require LLM-augmentation expertise; it requires the foundation expertise that Volumes 1–8 document.
Why it matters anyway. The LLM-augmented overlay has become the most active area of search engineering through 2024–2026. For consultants and engineers working with clients in 2025–2027, the question is rarely whether to consider LLM augmentation — it's where to apply it and how to operate it. Clients ask about 'AI search'; they want guidance on RAG, conversational search, semantic reranking, generative synthesis. Volume 9 is the reference for those conversations.
The structural caveat. LLM augmentation is an overlay on the foundations from Volumes 1–8, not a replacement. Teams that try to apply Volume 9 patterns without Volume 1 (architecture), Volume 5 (evaluation), and Volume 6 (operations) will produce systems that are unreliable, unmaintainable, and expensive. Volume 9's patterns assume the foundations are in place. The optional designation is honest: skip this volume if you're not ready, but don't skip Volume 6 because you adopted Volume 9. The dependencies run one direction only.
The currency challenge. Volume 9 will date faster than Volumes 1–8. The fundamentals of architecture, query understanding, indexing, ranking, evaluation, operations, UX, and platforms (Vols 1–8) change slowly; the practices documented are stable for years. The LLM-augmented patterns change rapidly; specific techniques and recommended models will shift within months. Volume 9 represents the state of practice in mid-2026; a future revision will look different. The volume is designed with this in mind — emphasizing durable underlying patterns (retrieval + LLM, two-stage rerank, cascade architectures) over specific implementations that change.
How Volume 9 integrates with the rest. The pipeline framing from Volume 1 still applies; LLM patterns slot into specific stages. The evaluation discipline from Volume 5 still applies; LLM augmentation adds new metrics (faithfulness, citation correctness) but the methodology is the same. The operational discipline from Volume 6 still applies; LLM operations is Volume 6 plus the new concerns documented in Section G. The UX patterns from Volume 7 still apply; conversational synthesis is Section G of Volume 7, expanded in Section D of Volume 9. The platform decisions from Volume 8 still apply; LLM augmentation is now a comparison dimension. Volume 9 isn't separate from the eight-volume foundation; it's the modern overlay on it.
The consulting consequence. For consulting engagements, Volume 9 is the volume clients increasingly ask about — sometimes before they\'ve established the foundations. The discipline is sequencing the conversation correctly: the engagement starts with foundation assessment (Volumes 1, 5, 6); the LLM-augmentation question follows naturally. Clients that want to skip straight to AI search without operational maturity should be redirected to build the foundations first; clients with mature foundations are well-positioned to benefit from selective LLM augmentation.
Appendix D — The Complete Library Reflection
With Volume 9 delivered, the Search Engineering Series spans nine volumes. The structural shape is unchanged from the eight-volume completion in Volume 8 — the foundations remain Volumes 1–5, the integration remains Volume 6, the UX translation remains Volume 7, the platform survey remains Volume 8 — plus Volume 9 as the LLM-augmented overlay.
Reading recommendation by role. For a search engineer joining a team: Volumes 1, 5, 6 for foundations; Volume 7 for UX; Volume 9 only if LLM-augmented work is imminent. For a search consultant: the full library, with Volume 9 as the modern-engagement supplement. For a UX designer working on search: Volume 7 plus selected chapters of Volumes 1, 2, 4, and Volume 9 (Section D specifically) for conversational interfaces. For an engineering leader: Volume 1 for vocabulary, Volume 5 for measurement framing, Volume 6 for operational expectations, Volume 8 for platform decisions, and Volume 9 to understand the LLM-augmented landscape clients increasingly ask about.
The series at this point. Nine volumes, approximately 500 pages. The volumes are reference material, not textbook material; chapters and sections are consumed when relevant to current work. The series doesn't replace specialist depth in any single area; it provides the cross-disciplinary connective tissue that's otherwise hard to assemble. The value-add is the breadth across the disciplines, organized to enable the consulting and engineering work the foundations support.
What's next. The series is structurally complete with Volume 8; Volume 9 is the optional extension. Beyond Volume 9, future work is revisions rather than new volumes: keeping Volume 9 current as LLM-augmentation practice evolves; updating Volume 8 as platforms change; refining all volumes based on practitioner feedback. The nine-volume library is the working completeness; revisions will keep it current. The structural shape is stable.
— End of The LLM-Augmented Search Catalog (Volume 9, optional) —
— End of the Search Engineering Series (Volumes 1–9) —