The Query Understanding Catalog
Turning raw queries into structured signals: tokenization, spell correction, parsing, intent, entities, rewriting, expansion.
About This Catalog
This is Volume 2 of the Search Engineering Series, covering query understanding — the discipline of processing raw user queries into structured signals that downstream retrieval and ranking can effectively consume. Where Volume 1 documented query-time architectural patterns and treated the query understanding stage as a black box, this volume opens that black box. The methods documented here produce the signals that Volume 1's query routing consumes (Section E of Volume 1), that Volume 4's ranking features depend on (Section C of Volume 4), and that Volume 5's evaluation methods measure for quality (the upstream signal quality affects downstream metrics).
Query understanding is the leftmost stage of the query-time pipeline and the area where production search teams most consistently underinvest. A retrieval system with mediocre query understanding hands its downstream stages a degraded input; no amount of retrieval sophistication or ranking quality can fully compensate. A retrieval system with excellent query understanding produces structured signals that let every downstream stage do its job better. The investment in query understanding typically produces outsized returns relative to its cost, especially for teams that have made significant retrieval and ranking investments but left query understanding underdeveloped.
The volume's perspective. Query understanding spans natural language processing, information retrieval, and machine learning. The discipline draws from each but isn't identical to any. NLP provides the methods (tokenization, NER, classification); IR provides the application context (these methods serve search); ML provides the modern training and inference infrastructure. The catalog covers the methods as patterns for search-specific use — not the general NLP literature — with concrete production examples and operational guidance.
Scope
Coverage:
- Tokenization and normalization: the analyzer chain (CharFilter / Tokenizer / TokenFilter); language-specific tokenization; stemming and lemmatization; ASCII folding and accent normalization.
- Spell correction: edit-distance methods; phonetic methods (Soundex, Metaphone); data-driven correction from query logs; LLM-based correction.
- Intent classification: rule-based, ML-based, and LLM-based approaches; Broder's taxonomy and modern extensions; confidence-based routing.
- Entity recognition and linking: NER for search; domain-specific entity types (brands, products, categories); entity linking to catalogs and knowledge bases; slot filling for structured queries.
- Query rewriting: synonym expansion; stop word handling; query reformulation rules; query reduction for long queries.
- Query expansion: manual synonym lists; co-click expansion from logs; embedding-based expansion; LLM-generated expansions.
- Personalized query understanding: user context as disambiguation signal; session-based query reformulation.
Out of scope (covered in other volumes):
- Retrieval architectures that consume query understanding output. Volume 1 covers.
- Indexing and document engineering (the index-time analyzer chain mirrors the query-time analyzer but operates on documents). Planned Volume 3.
- Ranking methods that use query understanding output as features. Volume 4 covers.
- Evaluation methods that measure query understanding quality. Volume 5 covers.
- Day-to-day operations (zero-result handling driven by query understanding failures). Planned Volume 6.
- Search UX (autocomplete, did-you-mean presentation, faceted refinement). Planned Volume 7.
How to read this catalog
Part 1 ("The Narratives") is conceptual orientation: what query understanding is and where it sits; the tokenization-analyzer chain that anchors lexical processing; spell correction and query rewriting as input-normalization disciplines; intent classification and entity recognition as the structured-signal-extraction disciplines; query expansion as the vocabulary-bridging discipline. Five diagrams sit in Part 1.
Part 2 ("The Substrates") is the pattern reference, organized by section. Each section opens with a short essay on what its patterns share. Representative patterns appear in the Fowler-style template with concrete code examples for the central methods.
Part 1 — The Narratives
Five short essays orient the reader to query understanding as engineering discipline. The reference entries in Part 2 assume the vocabulary established here.
Chapter 1. What Query Understanding Is
Query understanding is the discipline of processing raw user queries into structured signals. The raw query is a string — perhaps a sequence of words, perhaps a phrase, perhaps a question, perhaps something garbled with typos and shorthand. The structured signals are everything downstream stages need to do their work well: which tokens to match, what the user's intent is, what entities the query references, what synonyms and expansions might help. The pipeline turns the former into the latter; this volume catalogues the methods.
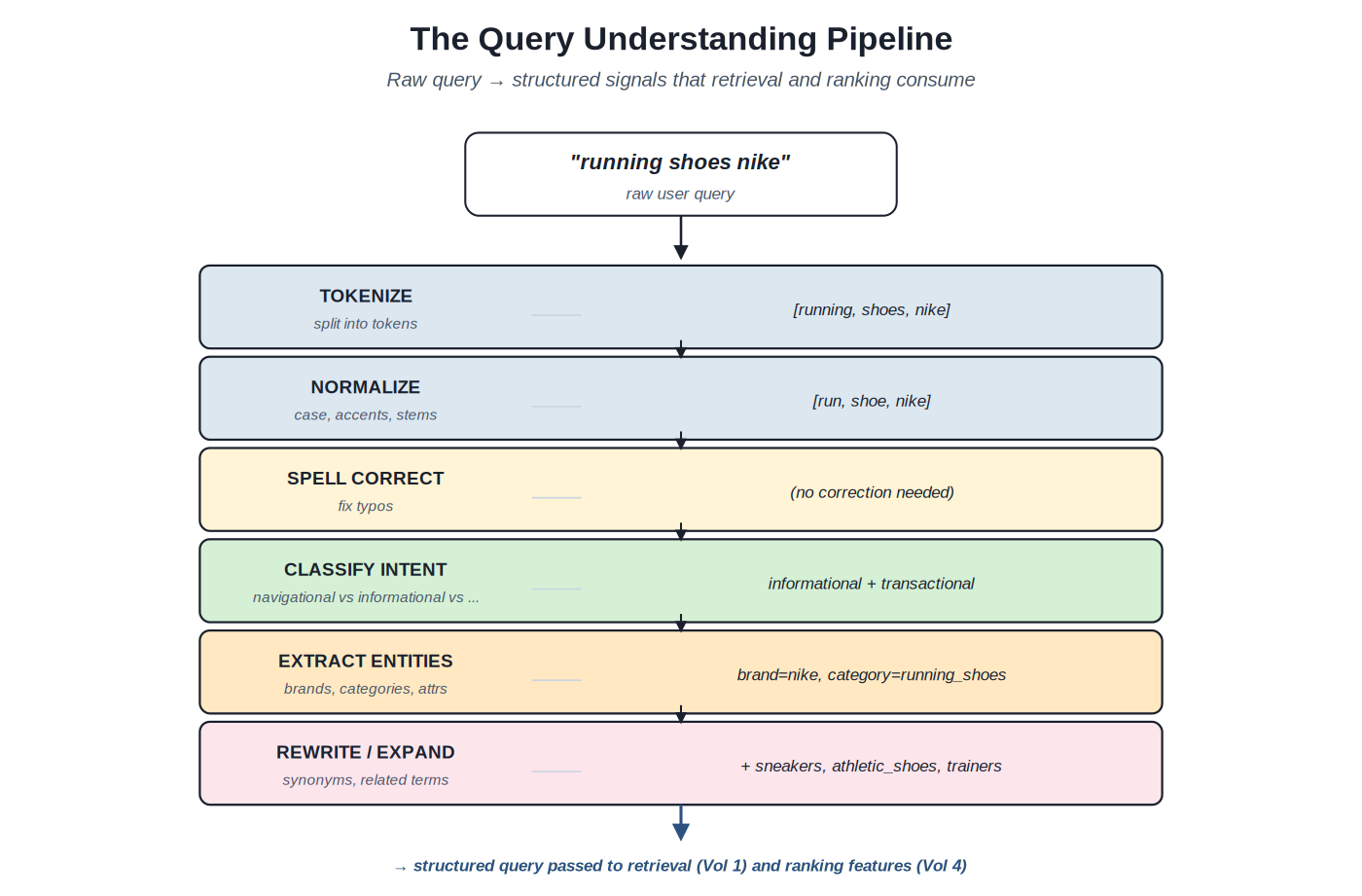
{kind=link}
Raw query → tokenize → normalize → spell correct → classify intent → extract entities → rewrite/expand → structured query.
The pipeline's position in the broader search architecture. Volume 1 Chapter 1 introduced the query-time pipeline as four stages: query understanding, retrieval, ranking, presentation. This volume covers the first stage in depth. The output of query understanding feeds: query routing (Volume 1 Section E) which selects retrieval architecture based on classified intent; retrieval methods (Volume 1 Sections A–D) which consume the tokenized and normalized query; ranking models (Volume 4) which use intent classification, entity extraction, and query characteristics as features; evaluation infrastructure (Volume 5) which measures whether the query understanding output is producing better downstream outcomes.
Why query understanding is underdeveloped. The discipline is technically less glamorous than the methods downstream. Tokenization is foundational but not novel; spell correction is necessary but rarely impressive; intent classification is useful but often invisible. Production teams that have invested heavily in retrieval (hybrid retrieval, vector search) and ranking (LTR, cross-encoder reranking) often have rudimentary query understanding: default Lucene tokenizers, no spell correction, no intent classification, ad-hoc synonym lists. The disparity is visible in their evaluation data — specific query classes consistently underperform because query understanding is producing poor input to the rest of the pipeline.
Why query understanding investment pays. A query understanding investment improves every downstream stage simultaneously. Better tokenization produces better retrieval candidates. Spell correction recovers queries that would otherwise return zero results. Intent classification enables query routing that fits queries to appropriate retrieval architectures. Entity extraction produces structured signals that retrieval can use as filters and ranking can use as features. The investments compound: query understanding improvements lift all downstream metrics rather than improving only one specific stage.
The volume's structure. The narratives in Part 1 progress through the pipeline stages: tokenization and normalization (Chapter 2), spell correction and rewriting (Chapter 3), intent classification and entity recognition (Chapter 4), query expansion (Chapter 5). Each chapter establishes the discipline conceptually; Part 2 documents the specific patterns. The progression matches the pipeline's data flow — readers can follow a query through the stages as the narratives unfold.
Chapter 2. Tokenization and Normalization
Tokenization is the foundational operation of lexical search. The raw query is a string; tokenization splits it into discrete tokens that the inverted index can match against. The choice of tokenization affects everything downstream: which tokens exist to be matched, what variations are unified, what gets discarded. Normalization handles the variations within tokens — case, accents, suffixes — to ensure that queries and documents match despite surface differences.
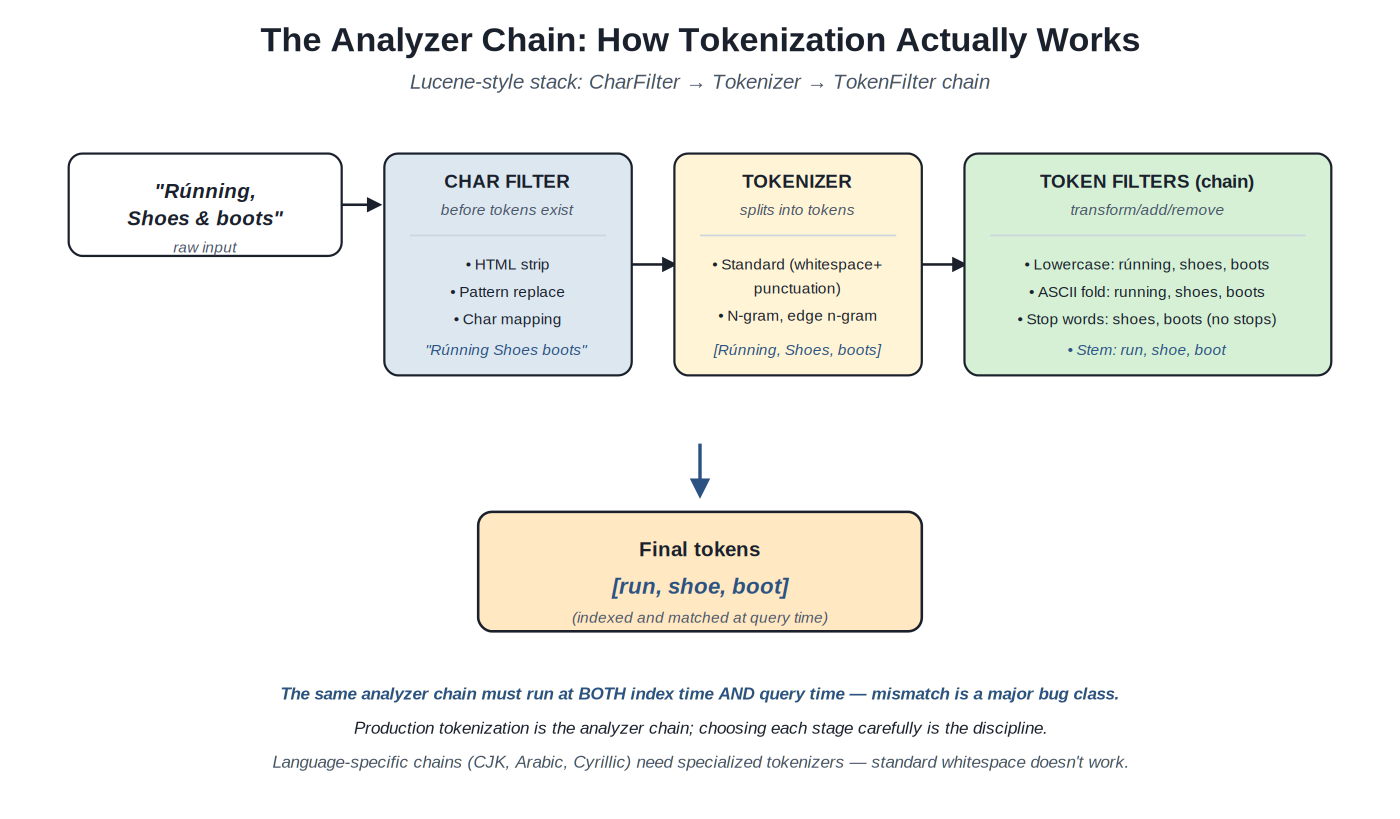
{kind=link}
Lucene-style analyzer stack: CharFilter operates before tokenization; Tokenizer splits; TokenFilters transform the resulting tokens.
The analyzer chain is the canonical structure. Lucene-based engines (Elasticsearch, OpenSearch, Solr) organize analysis as a stack: CharFilters operate on the raw character stream before tokens exist (HTML stripping, character mapping); a Tokenizer splits the character stream into tokens (whitespace-based, n-gram, language-specific); TokenFilters chain after the tokenizer to transform tokens (lowercase, stem, stop word remove, synonym expand). The same chain runs at index time (when documents are added to the index) and at query time (when queries are processed); mismatches between index-time and query-time analysis are a major bug class — documents indexed with one analyzer chain become invisible to queries processed with a different chain.
Tokenization choices. The standard tokenizer splits on whitespace and punctuation: "running shoes, nike" becomes [running, shoes, nike]. The choice handles English-like languages well but fails for languages without spaces between words (Chinese, Japanese, Korean — collectively "CJK"). CJK languages need specialized tokenizers that segment based on morphological analysis. Domain-specific tokenization may be needed for product SKUs ("ABC-123" should sometimes be a single token, sometimes two), camelCase ("iPhoneCase" should sometimes split, sometimes not), email addresses, hashtags. The choice of tokenizer should match the workload's linguistic characteristics.
Normalization choices. Case normalization (lowercasing) is nearly universal — "Nike" and "nike" should match. Accent normalization (Unicode normalization, ASCII folding) handles diacritics: "cañón" and "canyon" and "canon" may or may not need to match depending on the language and use case. Stemming reduces morphological variants to a root: "running", "ran", "runs" all map to "run" using a Porter stemmer or Snowball stemmer; the variants now match each other. Lemmatization is morphologically more sophisticated than stemming — it uses dictionary lookups and grammatical analysis — but is slower and less commonly applied at search-engine scale.
Production tokenization patterns. Match the analyzer to the language: use language-specific tokenizers for each language in the corpus. Apply stemming for stem-friendly languages (English, German, Spanish) and skip it where stems are less reliable. Apply ASCII folding when the corpus mixes accented and unaccented forms. Maintain multiple analyzer chains per field when needed: one for exact match (lighter normalization), one for stemmed match (full normalization), and search both with appropriate weighting. Track tokenization changes carefully — they change what's findable, and a tokenization change applied at query time without re-indexing produces a broken system until the index is rebuilt.
Chapter 3. Spell Correction and Query Rewriting
Users mistype queries. Some misspellings are obvious ("nkie" for "nike"); some are subtle ("it's" vs "its"); some are systematic ("sneekers" for "sneakers"). Spell correction recovers these queries before they hit retrieval; without it, misspelled queries return zero results or wildly wrong matches, and the search system fails the user without explanation. Query rewriting is the broader discipline of transforming the user's query into a form better suited to retrieval — handling not just typos but also synonyms, stop words, and query reformulation.
Spell correction methods. Three families dominate. Edit-distance methods compute the Levenshtein or Damerau-Levenshtein distance between the query token and dictionary terms; candidates within a small distance (typically 1 or 2 edits) are corrections. The dictionary is typically the index's term vocabulary — if the misspelled token isn't in the index but a nearby token is, the nearby token is the correction. Phonetic methods (Soundex from 1918, Metaphone from 1990, Double Metaphone from 2000) reduce tokens to phonetic codes; tokens that sound alike get similar codes. Phonetic methods catch errors that edit-distance misses ("philip" vs "filip" differ by 1 character but sound identical; phonetic methods handle this naturally). Data-driven methods learn corrections from query log patterns: queries that are reformulated by the same user shortly after produce candidate correction pairs; aggregated across many users, the patterns reveal common misspellings.
Modern spell correction. LLM-based spell correction emerged through 2023-2025 as a practical option: ask the model to correct the query. The pattern handles context ("apple corp" corrected differently from "apple fruit"), multi-word errors, and unusual misspellings that simpler methods miss. The trade-off is latency and cost; LLM calls in the query path add 100–500ms unless carefully optimized. Production deployments often combine: fast edit-distance correction as the default, LLM-based correction as a fallback when the simple methods fail or when query complexity suggests it would help.
Query rewriting beyond spell correction. The broader discipline includes: synonym expansion (replacing query terms with synonyms or adding synonyms to the query); stop word handling (removing "the", "and", "or" from queries where they don't contribute, except in phrase contexts where they do); query reformulation (changing the query structure based on rules — "red running shoes" might become "color:red category:running_shoes" for an e-commerce system); query reduction (truncating very long queries to their most important terms when the full query doesn't match well). Each rewriting decision affects retrieval behavior; the discipline is choosing rewrites that improve outcomes rather than degrading them.
Did-you-mean UX. Spell correction often produces user-visible UX: "Showing results for 'sneakers'. Search instead for 'sneekers'." The UX matters — users who entered "sneekers" as a deliberate misspelling shouldn't be force-corrected without recourse. Production patterns: auto-correct only with high confidence (the corrected form is much more popular and the user's form returns zero or few results); show did-you-mean prompts with lower confidence; never auto-correct identifiable user intent (proper nouns, specific product codes). The future Search UX Patterns Catalog covers the UX patterns in depth; the volume covers the correction methodology underneath.
Chapter 4. Intent Classification and Entity Recognition
Tokenization and spell correction produce a cleaner version of the query. Intent classification and entity recognition produce structured signals on top: what kind of query is this (intent), and what specific things does it reference (entities). The structured signals enable everything downstream that depends on understanding the query at more than a lexical level: query routing, per-intent ranking weights, structured filter application, faceted UX.
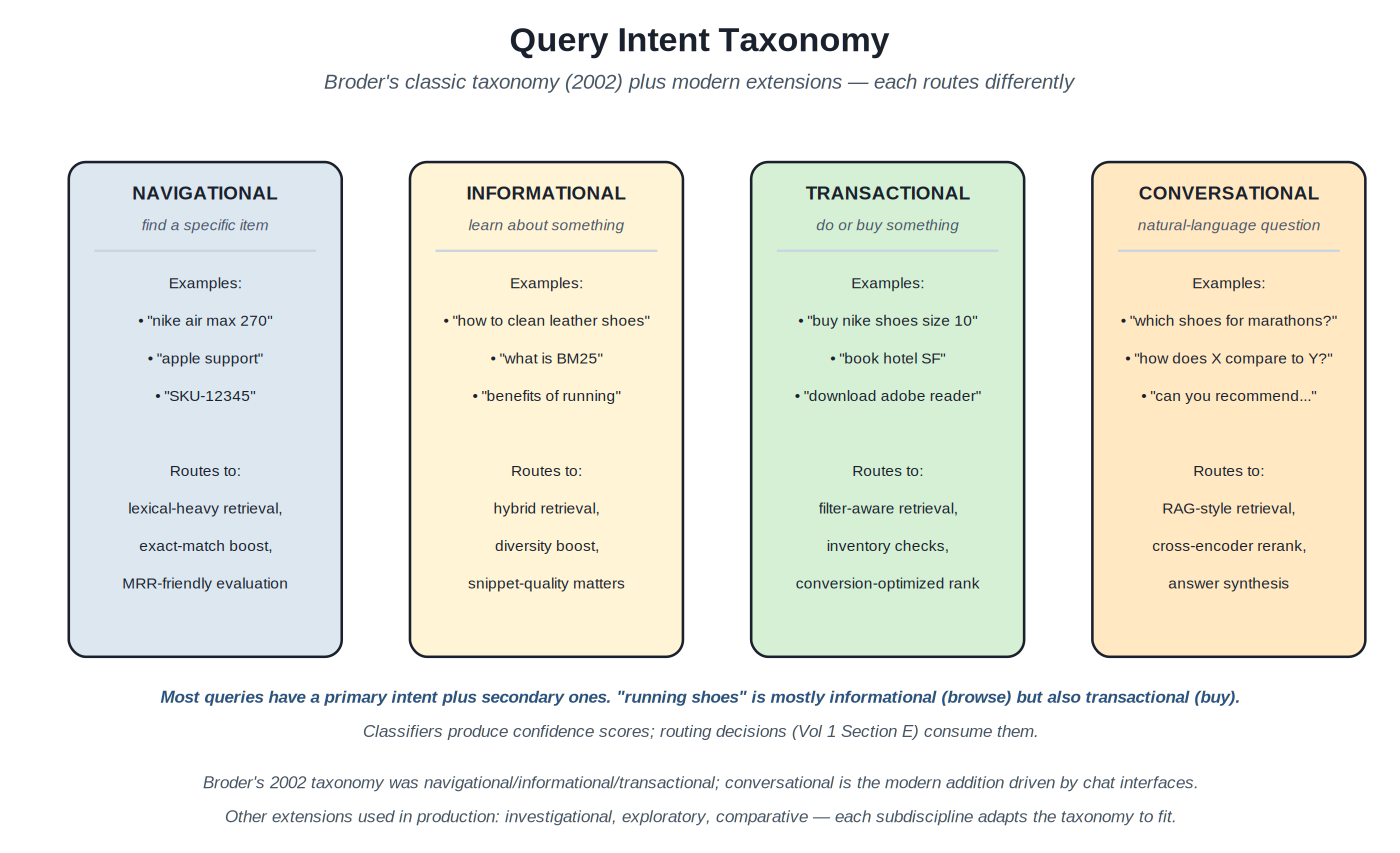
{kind=link}
Broder's 2002 taxonomy plus modern conversational extension. Each intent class routes differently.
The intent taxonomy. Andrei Broder's 2002 paper "A Taxonomy of Web Search" established the classic three-class taxonomy: navigational (find a specific thing), informational (learn about something), transactional (do or buy something). The taxonomy has held up well over two decades; modern extensions add conversational (natural-language questions), investigational (research with comparison), or domain-specific classes as needed. The taxonomy is a starting point; production systems often have their own taxonomies tailored to their workload.
Intent classification methods. Three families. Rule-based methods use heuristics: queries with question words ("how", "why", "what") are conversational; queries with explicit product codes are navigational; queries with multiple modifying adjectives are informational. Rule-based methods are simple, interpretable, and cheap; they're also brittle and don't generalize well across query distributions. ML-based methods train classifiers (logistic regression, gradient boosting, transformer-based) on labeled query examples; the methods generalize better but require training data. LLM-based methods prompt a model directly: "Classify this query as navigational, informational, transactional, or conversational." LLM-based classification handles unusual queries well and adapts to taxonomy changes via prompt updates; the trade-off is latency and cost.
Confidence and routing. Intent classifiers produce confidence scores; routing decisions (Volume 1 Section E) consume them. High-confidence classifications route directly to the designated retrieval architecture; low-confidence classifications can run multiple pipelines in parallel and fuse, or fall back to a default architecture. The discipline of confidence-aware routing is itself substantial; production systems calibrate confidence thresholds based on observed routing quality and downstream outcomes.
Entity recognition. Named Entity Recognition (NER) identifies spans of the query that refer to specific entity types: brands ("nike"), products ("air max 270"), categories ("running shoes"), attributes ("size 10", "mens"), locations, persons, organizations. Generic NER tools (spaCy, Stanford NER, BERT-based NER) handle standard entity types (PERSON, ORG, LOC); domain-specific NER requires training on labeled data from the specific domain. The output is the query annotated with entity spans and types.

{kind=link}
NER identifies entity spans; entity linking resolves them to catalog or knowledge-base IDs.
Entity linking. NER identifies that "nike" is a brand reference; entity linking resolves the reference to a specific brand ID in the company's catalog or knowledge base. The linking step is what makes entities useful for retrieval and ranking: a resolved brand ID can be applied as a structured filter, used as a ranking feature, or shown as a facet in the UX. Linking is harder than NER — it requires a knowledge base and disambiguation rules — but unlocks structured behavior that pure NER doesn't.
Slot filling. The pattern of extracting structured query parameters from natural-language queries. "Flights from SFO to JFK on Tuesday" becomes [origin=SFO, destination=JFK, date=2026-05-26]. Slot filling combines entity recognition (identifying spans) with role assignment (this span is origin, that span is destination) and value normalization ("Tuesday" becomes a specific date in context). The discipline is essential for domains with structured query semantics: travel search, real estate, job search, structured e-commerce search. The methods range from rule-based pattern matching to LLM-based extraction; the latter has emerged as the strongest approach for slot filling through 2024–2026.
Chapter 5. Query Expansion and Synonyms
Users don't always use the same vocabulary as the documents they're searching for. A user searching "pain reliever" wants documents about "analgesic", "ibuprofen", "acetaminophen". A user searching "sneakers" wants matches on "running shoes", "athletic footwear", "trainers". Query expansion is the discipline of bridging vocabulary gaps: adding related terms to the query (or to the document representation) so matches succeed despite vocabulary mismatch.
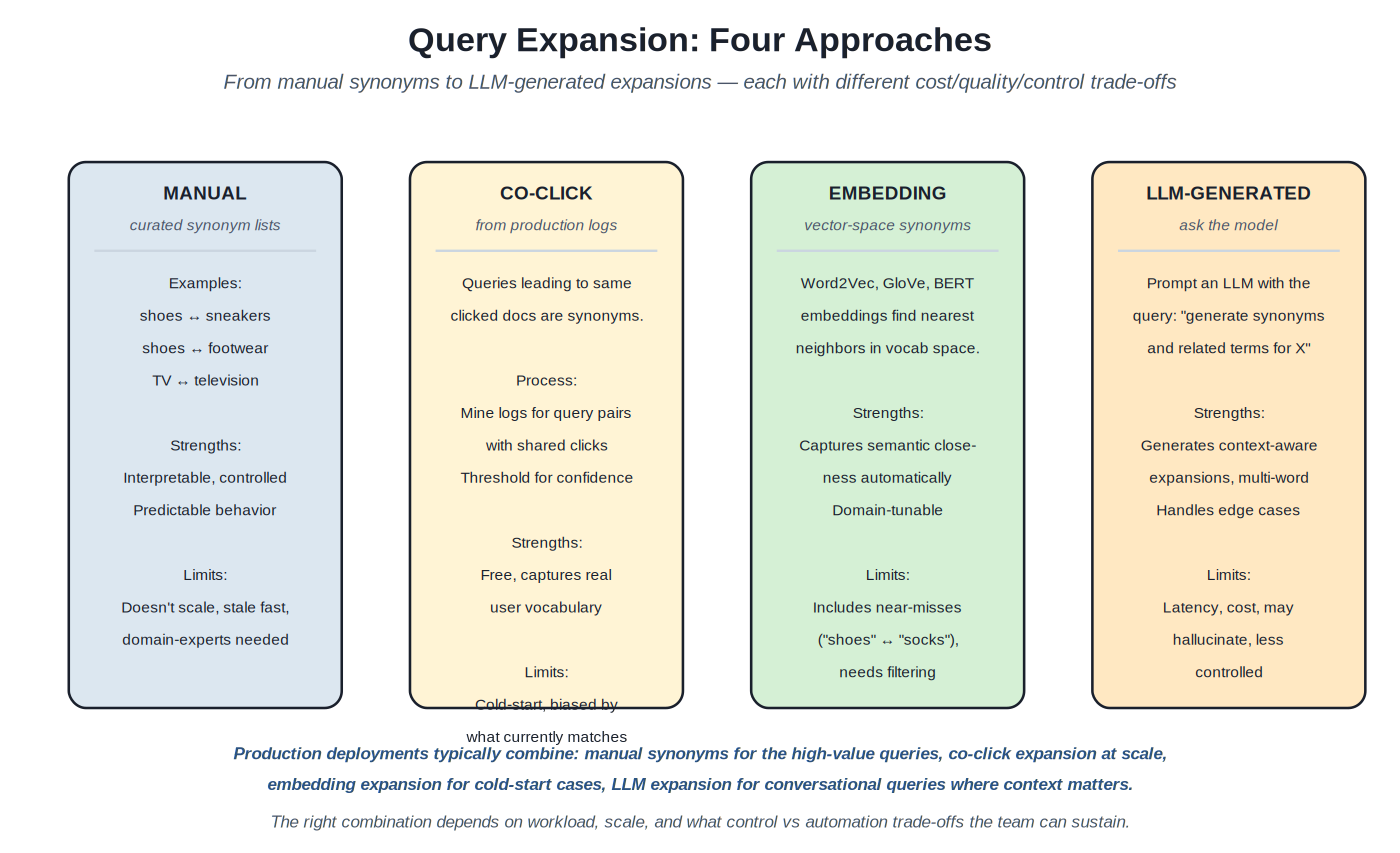
{kind=link}
Four approaches with different cost, quality, and control trade-offs.
Manual synonyms. The classical approach: maintain explicit lists of synonyms ("shoes ↔ sneakers ↔ footwear") that the analyzer chain expands at index time, query time, or both. The pattern is interpretable, controlled, and predictable. The limits are scaling: manual synonym lists don't generate themselves; domain experts must build and maintain them. For high-volume e-commerce or specialized domains where synonyms drive substantial revenue, the investment is justified; for smaller workloads, the maintenance overhead may exceed the value.
Co-click expansion from logs. Production click data reveals synonyms implicitly: when queries A and B lead to clicks on the same documents at high rates, A and B are likely synonyms. The method requires production query and click logs (Volume 5 Section C covers the data infrastructure). Mining is straightforward: group queries by clicked documents; identify query pairs with high shared-click rates; threshold for confidence. The expansion is free at scale and captures actual user vocabulary; the limit is cold-start (new domains without click history can't use this) and self-reinforcing bias (queries that the current system already handles well will dominate).
Embedding-based expansion. Word2Vec, GloVe, or modern BERT/sentence-transformer embeddings produce vector representations of vocabulary terms; nearest neighbors in the embedding space are semantically related. The expansion looks up the query's tokens in the embedding space and adds nearby tokens. The pattern captures semantic similarity automatically and works for cold-start (the embeddings come from pretrained models). The limit is precision: nearest-neighbor in embedding space includes near-misses ("shoes" and "socks" are semantically related but expanding the query for shoes to include socks is wrong) that require filtering.
LLM-generated expansion. Ask the model: "Generate synonyms and related terms for the query: red running shoes." The LLM produces context-aware expansions that earlier methods miss: multi-word phrases, idiomatic equivalents, brand-specific terminology. The pattern handles edge cases that other methods struggle with. The trade-offs: latency (LLM calls add 100–500ms to the query path), cost (per-query LLM cost adds up at scale), hallucination (the model may produce expansions that are plausible but wrong for the specific context), and less control (LLM expansions can't easily be inspected and curated the way manual synonyms can).
Combination patterns. Most production deployments combine multiple methods. Manual synonyms for high-value queries where exact control matters; co-click expansion at scale for the long tail; embedding expansion for cold-start cases; LLM expansion for conversational queries where context matters. The combination produces broader coverage than any single method while preserving control where it matters most. The right combination depends on workload, scale, and what control vs automation trade-offs the team can sustain.
Part 2 — The Substrates
Eight sections cover the patterns and methods of query understanding. Each section opens with a short essay on what its patterns share. Representative patterns appear in the Fowler-style template with code examples for the central methods.
Sections at a glance
- Section A — Tokenization and normalization patterns
- Section B — Spell correction patterns
- Section C — Query rewriting patterns
- Section D — Intent classification patterns
- Section E — Entity recognition and linking
- Section F — Query expansion patterns
- Section G — Personalized query understanding
- Section H — Discovery and resources
Section A — Tokenization and normalization patterns
The analyzer chain that anchors lexical processing in production search
Tokenization and normalization happen in every search system, often as defaults that the team didn't explicitly choose. The patterns in this section make the choices explicit: which tokenizer for which language and domain, which token filters in which order, when stemming helps and when it hurts. The analyzer chain is the foundation that downstream stages depend on; getting it right matters more than most teams realize.
The Lucene-style analyzer chain #
Source: Apache Lucene; Elasticsearch, OpenSearch, Solr analyzer documentation; Manning et al., Introduction to Information Retrieval
Classification — The structural pattern for production tokenization: CharFilter → Tokenizer → TokenFilter chain that runs at both index time and query time.
Process query and document text into matchable tokens using a configurable chain of character-level filters, tokenization, and per-token transformations, with the same chain applied at index time and query time to ensure consistent matching.
Default tokenizers handle the basic case (split on whitespace and punctuation; lowercase) but miss everything that makes production search work well. Language-specific tokenization, domain-specific token handling (SKUs, identifiers, mixed scripts), stemming choices, stop word handling, ASCII folding for international content — all of these require explicit configuration. The cost of getting it wrong is invisible matches: documents that should match a query don't because the analyzer chain produced different tokens for the query than for the document. The cost of inconsistent chains (different processing at index time vs query time) is the same failure mode at higher impact.
CharFilter stage. Operates on the raw character stream before tokens exist. Used for: HTML stripping (remove HTML tags from indexed content); pattern replacement (regex-based character substitutions); character mapping (map specific characters to others, like normalizing curly quotes to straight quotes). The stage is rarely the bottleneck but matters when the input has structured markup or character variations the downstream stages can't handle.
Tokenizer stage. Splits the character stream into tokens. Lucene provides many built-in tokenizers: standard (whitespace + punctuation, good for Western languages); keyword (no splitting; the entire input is one token); n-gram (produces overlapping character n-grams, useful for substring matching); edge n-gram (n-grams anchored to word starts, useful for autocomplete); language-specific tokenizers for CJK (Chinese/Japanese/Korean) languages that don't use whitespace; ICU tokenizer for sophisticated multi-language handling. The choice depends on the language and the matching behavior wanted.
TokenFilter chain. Token-level transformations applied in sequence. Common filters: lowercase (case normalization); ASCII folding (remove diacritics: café → cafe); stop word removal (filter out "the", "and", etc.); stemming (Porter for English, Snowball for multi-language; reduces morphological variants to a root); synonym expansion (add synonyms inline using a SynonymGraphFilter); n-gram (produce character n-grams for substring matching); shingle (produce token n-grams for phrase-like matching). Order matters: lowercase before stemming (stemmers expect lowercase input); ASCII fold before stemming for non-English languages.
Index-time vs query-time analyzers. The most common deployment uses the same analyzer at both times — the document's tokens are produced by the same chain that processes queries against it. Mismatches cause invisible matches: documents indexed with stemming match queries processed without stemming only when the query already contains the stemmed form. Some patterns deliberately use different chains: less aggressive query-time analysis (the user's exact query terms are preserved) with more aggressive index-time analysis (multiple synonym expansions baked into the index). The asymmetry is intentional and documented; accidental asymmetry is a bug.
Per-field analyzers. Different fields may need different analyzers. A product title gets standard tokenization with stemming; a product SKU field gets keyword tokenization (no splitting, exact match); a description field gets stemming and stop word removal; a brand field gets keyword tokenization with case normalization. The per-field approach lets each field's matching behavior be tuned independently; production teams often have 5–10 distinct analyzer configurations in a mature schema.
Multilingual content. Mixed-language corpora need careful analyzer design. Options: detect language at index time and apply language-specific analyzers per document (works when language is identifiable); use ICU tokenizer with multi-language token filters (works for many cases but loses some language-specific behavior); use the same analyzer for all languages and accept reduced quality on non-dominant ones (simple but limiting). The best choice depends on the language distribution and the importance of each language to the workload.
Every production search system has an analyzer chain whether the team configured it deliberately or not. The pattern applies universally; the question is whether the configuration was explicit and validated or accepted as default. Teams that have not validated their analyzer configuration typically have known unknowns in their search quality.
Alternatives — keyword-only matching (no tokenization or normalization) for specific fields where exact match is required. Pure vector matching (Volume 1 Section B) bypasses the analyzer chain entirely; some production systems use vector matching as primary retrieval with lexical matching as fallback. The analyzer chain remains foundational for the lexical portion of any hybrid system.
- Apache Lucene documentation (lucene.apache.org)
- Elasticsearch analyzer documentation
- OpenSearch analyzer documentation
- Solr analyzer documentation
- Manning et al., Introduction to Information Retrieval, ch. 2
Code
// Elasticsearch / OpenSearch custom analyzer for English e-commerce content
PUT /products
{
"settings": {
"analysis": {
"analyzer": {
"english_ecommerce": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": [
"lowercase",
"asciifolding",
"english_stop",
"english_stemmer",
"product_synonyms" // custom synonym filter, defined below
]
},
"keyword_lowercase": {
"type": "custom",
"tokenizer": "keyword",
"filter": ["lowercase"]
}
},
"filter": {
"english_stop": {
"type": "stop",
"stopwords": "_english_"
},
"english_stemmer": {
"type": "stemmer",
"language": "english" // Porter-like stemmer
},
"product_synonyms": {
"type": "synonym_graph",
"synonyms": [
"sneakers, running shoes, athletic shoes, trainers",
"tv, television",
"laptop, notebook computer"
]
}
}
}
},
"mappings": {
"properties": {
"title": { "type": "text", "analyzer": "english_ecommerce" },
"description": { "type": "text", "analyzer": "english_ecommerce" },
"brand": { "type": "text", "analyzer": "keyword_lowercase" },
"sku": { "type": "keyword" } // no tokenization; exact match only
}
}
}
// Test the analyzer with a sample query
GET /products/_analyze
{
"analyzer": "english_ecommerce",
"text": "Running Shoes & Sneakers for Mén"
}
// Expected output:
// [run, shoe, sneaker, athletic, shoe, trainer, men]
// (lowercased, ASCII-folded, stemmed, stop words removed, synonyms expanded)Section B — Spell correction patterns
Edit-distance, phonetic, and data-driven methods that recover misspelled queries
Misspelled queries are common — typical e-commerce search sees 5–15% misspellings in head queries and more in long-tail traffic. Without spell correction, these queries return zero results or wildly wrong matches; users see the system fail and either reformulate or give up. The patterns in this section recover misspelled queries by various methods: edit-distance lookups, phonetic codes, learned corrections from production logs.
Edit-distance and phonetic spell correction #
Source: Norvig, "How to Write a Spelling Corrector" (2007); classical IR literature; Soundex (Russell, 1918); Metaphone (Philips, 1990); production implementations across search platforms
Classification — Spell correction methods based on character-level similarity (edit distance) and phonetic similarity (sound-alike codes).
Identify and correct misspelled query tokens by finding nearby dictionary entries via Levenshtein/Damerau-Levenshtein distance or phonetic encoding, recovering queries that would otherwise return zero or poor results.
Users mistype queries: missing letters, swapped letters, doubled letters, mixed-up word boundaries. Some misspellings are obvious ("nkie" for "nike"), some subtle ("philip" vs "filip"), some systematic ("sneekers" for "sneakers"). Without correction, these queries fail; with correction, the system recovers them. The methods differ in what kinds of errors they catch and how they avoid over-correcting.
Levenshtein distance. The number of single-character edits (insertions, deletions, substitutions) required to transform one string into another. "nkie" → "nike" is distance 2 (two character swaps). "speling" → "spelling" is distance 1 (one insertion). Production spell correction typically uses distance ≤ 2 for short tokens (≤5 chars), distance ≤ 3 for longer tokens. Most candidate corrections are within distance 1-2; over-broad search produces too many candidates and hurts precision.
Damerau-Levenshtein distance. Extends Levenshtein to count adjacent-character swaps as a single edit. "hte" → "the" is distance 1 in Damerau-Levenshtein (one swap), but distance 2 in pure Levenshtein. Damerau is closer to how humans actually mistype; production correctors typically use Damerau.
The dictionary. Spell correction needs a dictionary of valid tokens. The pragmatic choice for search: use the index's term vocabulary. Any token in the index is presumed valid; tokens not in the index are correction candidates. The choice avoids over-correcting domain-specific terms (the index already contains them) and under-correcting common misspellings (they're not in the index because they're wrong). The vocabulary is typically filtered by term frequency — only terms above a frequency threshold are candidate corrections, to avoid suggesting rare typos in the index as corrections.
Soundex. The earliest phonetic algorithm (1918, originally for census records). Reduces a token to a 4-character code based on consonants: "Robert" → "R163", "Rupert" → "R163" (same code, sound similar). Tokens with the same Soundex code are phonetic matches. Soundex is limited to English-like languages and crude (it generates many false matches), but cheap and useful as a baseline phonetic method.
Metaphone and Double Metaphone. More sophisticated phonetic algorithms. Metaphone (1990) handles English phonetics more accurately than Soundex; Double Metaphone (2000) supports multiple language origins and produces two codes per token (for alternative pronunciations). "philip" and "filip" produce identical Metaphone codes; the methods catch this case that edit-distance struggles with (the strings differ by 1 character, but they sound identical, which is the relevant similarity).
Combining methods. Production spell correctors typically combine edit-distance and phonetic methods: take candidates with low edit distance AND/OR matching phonetic codes; rank candidates by combined score (lower distance is better; matching phonetic code is a boost); apply confidence thresholds for did-you-mean UX vs. auto-correction.
Confidence and UX integration. Spell correction confidence comes from the gap between the query token's frequency in the index (or in query logs) and the candidate correction's frequency. "nkie" has zero or very low frequency; "nike" has high frequency; the gap supports high-confidence auto-correction. "color" vs "colour" have similar frequencies; correction is ambiguous and should not auto-apply. Production systems use confidence thresholds: auto-correct above 95% confidence; show did-you-mean below; ignore below another threshold. The thresholds are tuned via A/B testing against user behavior signals.
Caching. Spell correction lookups are computationally non-trivial (edit-distance against a large vocabulary takes work). Production deployments cache correction results: query token → corrected token mappings, with cache invalidation when the index vocabulary changes. Cache hit rates are typically high (the same misspellings recur across many users), making correction nearly free for cached queries.
Every consumer-facing search system benefits from spell correction. E-commerce especially — misspelled product names and brand names are common; correction recovers significant query volume that would otherwise fail. Enterprise search where employees may be unfamiliar with internal terminology. The investment is modest and the returns are visible in zero-result rate reduction.
Alternatives — LLM-based correction (next entry) for cases needing context-aware correction. Pure ignore (no correction) for tightly controlled domains where misspellings shouldn't happen and are user errors that the system shouldn't silently fix. Most production search benefits from some form of correction; the choice is which method, not whether.
- Norvig, "How to Write a Spelling Corrector" (norvig.com/spell-correct.html)
- Damerau, "A technique for computer detection and correction of spelling errors" (1964)
- Philips, "Hanging on the Metaphone" (1990)
- Lucene FuzzyQuery and Solr Suggester documentation
- Manning et al., Introduction to Information Retrieval, ch. 3
Code
# Production spell correction combining edit-distance and phonetic methods
from difflib import get_close_matches
import jellyfish # for Metaphone
class SpellCorrector:
def __init__(self, vocabulary, min_frequency=10):
"""vocabulary: dict mapping token -> frequency from index/query logs"""
self.vocabulary = {
term: freq for term, freq in vocabulary.items()
if freq >= min_frequency
}
# Precompute Metaphone codes for all vocab terms
self.metaphone_index = {}
for term in self.vocabulary:
code = jellyfish.metaphone(term)
self.metaphone_index.setdefault(code, []).append(term)
def correct(self, token, max_distance=2):
# Already in vocabulary? No correction needed.
if token in self.vocabulary:
return None
# Find edit-distance candidates
edit_candidates = get_close_matches(
token,
self.vocabulary.keys(),
n=10,
cutoff=0.7 # rough threshold; tuned per workload
)
# Find phonetic candidates
try:
query_metaphone = jellyfish.metaphone(token)
phonetic_candidates = self.metaphone_index.get(query_metaphone, [])
except Exception:
phonetic_candidates = []
# Combine and score: prefer high-frequency candidates
candidates = set(edit_candidates) | set(phonetic_candidates)
if not candidates:
return None
# Rank by frequency in vocabulary (proxy for popularity)
ranked = sorted(
candidates,
key=lambda c: self.vocabulary[c],
reverse=True
)
best = ranked[0]
# Confidence: ratio of best candidate's frequency to misspelled token's frequency (~0)
# In practice, gate by frequency threshold rather than computing ratio
if self.vocabulary[best] >= 100: # confidence threshold; tuned per workload
return best
return None
def correct_query(self, query):
"""Correct each token in the query."""
tokens = query.lower().split()
corrections = {}
for tok in tokens:
corr = self.correct(tok)
if corr and corr != tok:
corrections[tok] = corr
return corrections
# Example usage
vocab = {'nike': 50000, 'shoes': 100000, 'running': 30000, 'sneakers': 25000}
corrector = SpellCorrector(vocab)
print(corrector.correct_query('nkie runing shoes'))
# Expected output: {'nkie': 'nike', 'runing': 'running'}Section C — Query rewriting patterns
Stop words, query reformulation, and the rewrites that improve match quality
Query rewriting transforms the user's query into a form better suited for retrieval. Stop word handling decides which terms to keep and which to drop. Reformulation rules apply explicit transformations ("red shoes" → "color:red category:shoes"). Query reduction handles long queries that don't match well at full length. The patterns share a structural feature: they alter what the retrieval stage sees, and getting them right requires careful tuning against evaluation data.
Stop words, query reformulation, and query reduction #
Source: Classical IR literature (Manning et al.); production patterns across search platforms; Grainger, AI-Powered Search
Classification — Rule-based and learned query rewriting that alters the query before retrieval.
Improve retrieval quality by transforming the user's query — removing low-value tokens, reformulating into structured forms, reducing overly-long queries — in ways that improve match quality without losing user intent.
Raw user queries often need modification before they're ideal for retrieval. Stop words ("the", "and", "of") contribute little to matching but add noise; removing them helps in most cases but hurts when they're part of phrases ("to be or not to be" needs the stop words). Long queries ("I'm looking for a really comfortable pair of black running shoes for marathon training that don't cost too much") don't match well at full length — too few documents contain all the terms. Specific phrasings ("red shoes") have implicit structure (color = red, category = shoes) that the retrieval system can use only if it's made explicit. Query rewriting handles these cases.
Stop word removal. Identify and remove low-value tokens from the query. Lucene and similar libraries provide language-specific stop word lists (English: a, an, the, and, or, of, in, on, ...). The removal happens in the analyzer chain (Section A). The pattern is appropriate for most cases but breaks for phrase queries where stop words are essential: "to be or not to be" loses its identity if stops are removed. Production systems often have multiple analyzer chains: stop-word-removing for general matching, stop-word-preserving for phrase matching, with appropriate query construction to use each.
Stop word handling for short queries. A short query that's entirely stop words ("where is", "what is") becomes empty after stop word removal, retrieving nothing. Production patterns: detect this case and fall back to preserving stops; or rewrite the query to add a synthetic non-stop-word; or trigger a different retrieval path that handles the case. The edge case is small but matters because users get confused when extremely short queries fail.
Query reformulation rules. Explicit rules that transform query patterns into structured queries. "red running shoes" might be rewritten as "color:red category:running_shoes" where the structured fields apply as boosts or filters. "Size 10 mens" might extract size=10, gender=mens as structured signals. The rules typically pattern-match against the query (after tokenization and entity recognition) and apply transformations. Production systems maintain rule sets ranging from dozens to thousands of rules depending on workload complexity.
Rule sources. Manual: domain experts encode known patterns. Learned: query log analysis surfaces common patterns where specific reformulations would have helped. LLM-suggested: prompt the model for likely reformulations of common queries. Production deployments often combine: manual rules for known high-value cases, learned rules for the long tail, LLM suggestions for new query types.
Query reduction. Long queries don't match well — too few documents contain all the terms. Reduction identifies the most important terms and drops the rest. Methods: IDF-weighted importance (keep high-IDF terms, drop low-IDF); entity-aware reduction (keep recognized entities, drop filler); learned reduction (a model trained to predict which terms to keep). The reduction is often applied as fallback: try the full query first; if too few results, retry with reduced query. Some systems run both in parallel and combine.
Phrase recognition. Multi-word phrases ("New York Times") should sometimes be treated as units rather than independent tokens. Phrase recognition identifies likely multi-word entities and treats them as quoted phrases. Methods: gazetteer-based (lookup against known multi-word entities); learned (a model trained on phrase-vs-not-phrase distinctions); LLM-based (prompt the model to identify phrases). The pattern is essential for proper noun handling and specific product/brand recognition.
Reformulation evaluation. Query rewrites change retrieval behavior; the changes need to be evaluated. The methodology from Volume 5: track per-rewrite metrics (does this rule improve outcomes for the queries it triggers on?); maintain golden query sets that include rewritten cases; A/B test substantial rule additions or changes. Production teams without evaluation discipline often accumulate rules that individually look helpful but collectively degrade quality; evaluation discipline prevents this drift.
Production search where user queries vary substantially in length, structure, and formality. E-commerce, enterprise search, customer service search, technical documentation search. Cases where query log analysis surfaces patterns that consistent rewriting would handle.
Alternatives — no rewriting (raw queries) for cases where users issue clean structured queries (advanced search interfaces, API search). LLM-based query rewriting (next-generation pattern) for cases needing context-aware transformations. Most production search benefits from some rewriting; the level of investment depends on workload complexity.
- Manning et al., Introduction to Information Retrieval, ch. 2
- Grainger, AI-Powered Search, chapters on query rewriting
- Coveo query pipeline documentation
- Algolia query rules documentation
Section D — Intent classification
Rule-based, ML-based, and LLM-based methods for classifying query intent
Intent classification produces the routing signal that Volume 1 Section E's query routing consumes. The methods range from simple rules to LLM-based classification; each has trade-offs in accuracy, latency, cost, and maintainability. Most production systems combine methods: rules for clear cases, ML/LLM for ambiguous ones.
Intent classification across rule, ML, and LLM approaches #
Source: Broder, "A Taxonomy of Web Search" (2002); Jurafsky and Martin, Speech and Language Processing; production methodology at major e-commerce and consumer search companies
Classification — Methods for classifying query intent into discrete classes (navigational, informational, transactional, conversational, ...) for routing and feature use.
Classify each query into intent classes with confidence scores, supporting downstream routing decisions and providing features for ranking models.
Different intents deserve different retrieval architectures. Navigational queries want exact-match-first retrieval; informational queries want hybrid retrieval with diversity; conversational queries want RAG-style retrieval. Without classification, the system applies one architecture to all queries, compromising results for at least some intents. Classification produces the signal that lets routing handle different intents differently.
Rule-based classification. Heuristics based on query characteristics. Examples: queries starting with question words (who, what, when, where, why, how) are informational or conversational; queries containing currency symbols or terms like "buy", "order", "price" are transactional; queries with single product names or SKUs are navigational; queries longer than ~6 tokens with natural-language structure are conversational. Rules are simple, interpretable, and cheap to evaluate; they produce clear classifications but don't generalize well to query distributions the rules weren't designed for.
Rule-based limitations. The rules need maintenance as query patterns evolve. New query types (e.g., emoji queries, voice-input queries with characteristic punctuation patterns) require rule updates. The rules also have correctness limits: "nike air max" doesn't obviously fit one rule but is clearly navigational; "good running shoes" doesn't obviously fit one rule but is clearly informational. Pure rule-based systems leave many queries miscategorized or unclassified.
ML-based classification. Train a classifier on labeled queries: each query labeled with its true intent class. The classifier learns features that correlate with each class. Standard ML methods: logistic regression for fast inference and interpretable feature importance; gradient boosting (LightGBM, XGBoost) for higher accuracy; transformer-based classifiers (BERT fine-tuned for classification) for highest accuracy at higher cost. Features can be hand-engineered (query length, presence of question words, token IDFs) or learned (encoder embeddings). The classifier produces a class label and a confidence score.
Training data. The classifier needs labeled training data: queries with intent labels. Sources: explicit annotation (an analyst labels a representative sample of production queries); pseudo-labeling from query behavior (queries that led to specific clicks/conversions can be auto-labeled with high confidence); LLM-generated labels (prompt an LLM to label each query, with expert validation on a sample). Production deployments typically combine: small expert-labeled gold set for validation; larger pseudo- or LLM-labeled set for training.
LLM-based classification. Prompt an LLM directly: "Classify the following query as navigational, informational, transactional, or conversational. Query: [...]". The LLM produces the class label and (with appropriate prompting) a confidence score or reasoning. The pattern handles unusual queries well, adapts to taxonomy changes via prompt updates rather than retraining, and integrates context naturally (LLMs can use additional context like user history if provided). The trade-offs: latency (LLM calls in the query path add tens of milliseconds even with optimized infrastructure), cost (per-query LLM cost adds up at scale), and consistency (LLM outputs can vary unless the model is pinned and temperature is zero).
Production deployment patterns. Most mature systems combine: rules for the easiest cases (queries that obviously fit one class, handled cheaply); ML classifier for the bulk of queries (good accuracy at low latency); LLM fallback for unusual queries that the rules and ML classifier are uncertain about. The combination produces high coverage at controlled cost; the routing infrastructure (Volume 1 Section E) consumes the output for retrieval architecture selection.
Confidence calibration. Classifiers produce confidence scores; the scores need to be calibrated so that "95% confident" actually means the right answer 95% of the time. Calibration methods: Platt scaling, isotonic regression, temperature scaling for transformer outputs. Well-calibrated confidence is essential for confidence-based routing decisions; poorly calibrated confidence produces routing failures that look like classification failures.
Multi-label classification. Some queries have multiple intents. "Running shoes" is partly informational (the user wants to know about options) and partly transactional (the user is likely shopping). Multi-label classification handles this by allowing each query to have multiple class assignments with separate confidence per class. The pattern is more accurate than forcing single-class assignment but produces routing complexity — if a query is 60% informational and 40% transactional, which architecture should it route to? Production systems handle this with hybrid architectures that serve both intents.
Production search with heterogeneous query types (most e-commerce, most consumer search, most enterprise search). Systems where different intents would benefit from different retrieval architectures or different ranking models. Cases where query log analysis shows that uniform handling produces worse outcomes for specific intent classes.
Alternatives — single-architecture deployment for narrow workloads with uniform query types. Implicit intent (the ranking model learns intent-correlated features without explicit classification). For diverse query distributions, explicit classification typically outperforms implicit handling.
- Broder, "A Taxonomy of Web Search" (SIGIR Forum, 2002)
- Jurafsky and Martin, Speech and Language Processing (3rd ed., free online drafts)
- Production methodology from search teams at e-commerce companies
- Coveo machine learning intent documentation
Code
# LLM-based intent classification (production pattern)
import anthropic
from enum import Enum
class Intent(Enum):
NAVIGATIONAL = "navigational"
INFORMATIONAL = "informational"
TRANSACTIONAL = "transactional"
CONVERSATIONAL = "conversational"
CLASSIFY_PROMPT = """Classify the following search query into one of four intent classes:
- navigational: User wants to find a specific item, brand, page, or known entity.
Examples: "nike air max 270", "apple support", "SKU-12345"
- informational: User wants to learn or browse without specific purchase intent.
Examples: "how to clean leather shoes", "benefits of running", "red running shoes"
- transactional: User explicitly wants to buy, book, or complete an action.
Examples: "buy nike shoes size 10", "book SFO to JFK flight", "download adobe reader"
- conversational: User asks a natural-language question expecting a synthesized answer.
Examples: "which shoes are good for marathons?", "how does Nike compare to Adidas?"
Query: "{query}"
Respond with JSON: {{"intent": "<class>", "confidence": <0-1>, "reasoning": "<brief explanation>"}}"""
client = anthropic.Anthropic()
def classify_intent(query: str) -> dict:
response = client.messages.create(
model="claude-haiku-4-5-20251001", # Haiku is fast/cheap; sufficient for classification
max_tokens=200,
temperature=0, # zero for consistency
messages=[{
"role": "user",
"content": CLASSIFY_PROMPT.format(query=query)
}]
)
import json
text = response.content[0].text.strip()
# Strip code-fence markdown if present
text = text.replace("```json", "").replace("```", "").strip()
try:
result = json.loads(text)
return {
"intent": Intent(result["intent"]),
"confidence": float(result["confidence"]),
"reasoning": result["reasoning"]
}
except (json.JSONDecodeError, KeyError, ValueError) as e:
# Fall back to a default class with low confidence on parse failure
return {
"intent": Intent.INFORMATIONAL,
"confidence": 0.0,
"reasoning": f"Parse failure: {e}"
}
# Hybrid pattern: rules first, LLM fallback
QUESTION_WORDS = {'who', 'what', 'when', 'where', 'why', 'how', 'which'}
TRANSACTIONAL_TERMS = {'buy', 'order', 'purchase', 'book', 'download'}
def classify_with_rules(query: str) -> dict | None:
tokens = query.lower().split()
if not tokens:
return None
if tokens[0] in QUESTION_WORDS and len(tokens) > 4:
return {"intent": Intent.CONVERSATIONAL, "confidence": 0.85, "reasoning": "Question word + length"}
if any(t in TRANSACTIONAL_TERMS for t in tokens):
return {"intent": Intent.TRANSACTIONAL, "confidence": 0.85, "reasoning": "Transactional term"}
return None # rules didn't fire; defer to LLM
def classify(query: str) -> dict:
result = classify_with_rules(query)
if result is not None:
return result
return classify_intent(query)Section E — Entity recognition and linking
NER, domain-specific entity types, and resolution to catalog/knowledge-base IDs
Entity recognition extracts spans of the query that refer to specific entities; entity linking resolves those spans to IDs in a catalog or knowledge base. Together they produce the structured signals that retrieval filters and ranking features depend on. The patterns documented here cover the production methods for both stages — from classical NER to modern LLM-based extraction.
Named entity recognition and entity linking for search #
Source: spaCy, Stanford NER for classical NER; BERT-NER and transformer-based NER for modern methods; production methodology at major e-commerce search companies
Classification — Methods for identifying entity spans in queries and resolving them to structured IDs.
Extract structured entity information (brands, products, categories, attributes, locations) from natural-language queries and link the extracted entities to IDs in the company's catalog or knowledge base, producing signals that retrieval and ranking can use as filters, boosts, and features.
A query like "nike air max 270 size 10 mens" contains structured information: BRAND=nike, PRODUCT_LINE=air_max_270, SIZE=10, GENDER=mens. Without entity extraction, the query is treated as a bag of words; downstream stages can match against the words but can't apply structured filters or use the structure as features. With entity extraction, the brand/size/gender become filters that narrow retrieval correctly, and the recognized entities become high-quality ranking features. The same applies across domains: travel search needs origin/destination/date; legal search needs jurisdiction/date/case-type; enterprise search needs people/teams/projects.
The two-stage architecture. NER identifies the spans; entity linking resolves them to IDs. Span identification: "nike" → BRAND, "air max 270" → PRODUCT_LINE, "size 10" → SIZE, "mens" → GENDER. Linking: BRAND span "nike" → brand_id=8421 (the catalog's ID for Nike Inc.); PRODUCT_LINE span "air max 270" → line_id=AM270. The two stages can be implemented separately (a generic NER model plus a domain-specific linker) or jointly (a model trained to predict the linked ID directly).
Classical NER. Tools like spaCy and Stanford NER provide pretrained models for standard entity types (PERSON, ORGANIZATION, LOCATION, DATE, MONEY). The pretrained models handle general cases but miss domain-specific entity types (BRAND, PRODUCT, ATTRIBUTE). For domain-specific entities, train a custom NER model on labeled examples from the domain.
Transformer-based NER. Fine-tuned BERT models (BERT-NER) handle NER as token classification: each token gets a tag (B-BRAND for "beginning of brand", I-BRAND for "inside of brand", O for "outside any entity"). The IOB tagging scheme handles multi-token entities cleanly. Fine-tuning needs labeled data: a few thousand annotated queries with entity spans typically suffices for good domain performance. The transformer architecture handles context better than classical methods, especially for ambiguous entities.
LLM-based NER. Modern LLMs handle NER with zero-shot or few-shot prompting. Provide the query and ask the LLM to identify entities: "Extract brands, products, categories, sizes, and gender mentions from this query: [...]. Return as JSON." LLM-based NER handles unusual entity types without retraining; it adapts to new entity types via prompt updates. The trade-offs are latency and cost; production deployments use LLM NER when other methods' quality is insufficient and the cost is justified.
Entity linking methods. Lookup-based: maintain a dictionary mapping surface forms to IDs ("nike", "Nike", "NIKE" → brand_id=8421). Simple, fast, requires manual maintenance. Embedding-based: encode both query entities and catalog entities into the same vector space; find nearest neighbor in catalog. Handles surface variations automatically; needs an embedding model that captures entity semantics. Learned linking: train a model that takes a query span and produces a catalog ID directly, using labeled training data. Most accurate; needs the most engineering investment.
Slot filling pattern. The pattern of extracting structured query parameters from natural-language queries. "Flights from SFO to JFK on Tuesday" becomes [origin=SFO, destination=JFK, date=2026-05-26]. Slot filling combines NER (identifying spans) with role assignment (this span is origin, that span is destination) and value normalization ("Tuesday" becomes a specific date). Modern slot filling typically uses transformer-based or LLM-based methods; the patterns from this entry apply with the addition of role-assignment logic.
Domain-specific design. Each domain has its own entity types and linking targets. E-commerce: brands, products, categories, sizes, colors, materials, gender, age-group, occasion. Travel: origins, destinations, dates, cabin classes, passenger counts. Legal: jurisdictions, case types, dates, statutes, courts. Enterprise: people, teams, projects, documents, dates. The entity inventory should be designed deliberately based on what retrieval and ranking need; over-broad entity inventories produce noise, under-broad inventories miss structured signals.
Evaluation. NER evaluation: precision (of extracted entities, what fraction are correct), recall (of true entities in queries, what fraction were extracted), F1 (the harmonic mean). Linking evaluation: of correctly extracted entities, what fraction linked to the right ID. Production deployments track both metrics and the downstream impact: do queries with successful entity extraction produce better retrieval outcomes? The downstream measurement (Volume 5 Section G covers business metrics) is the ultimate validation.
E-commerce search where structured query understanding drives substantial business value. Travel search where slot-filled parameters are essential. Legal and medical search where domain entities matter. Enterprise search where people, teams, and projects need recognition. Any domain where queries contain structured information that retrieval and ranking could use.
Alternatives — no entity extraction for narrow domains with simple query patterns. Pure lexical matching where structured signals don't add value. Most production search with diverse queries benefits from entity extraction; the level of investment depends on query complexity and downstream value.
- spaCy NER documentation (spacy.io)
- Hugging Face transformers NER documentation
- Production methodology from e-commerce search teams (Etsy, Wayfair, Amazon)
- Coveo named entity recognition documentation
Code
# E-commerce NER with spaCy + custom entity linking
import spacy
from spacy.tokens import Span
# For production: train custom NER on labeled domain data
# This example uses spaCy's NER with custom entity types defined via training
nlp = spacy.load("ecommerce_ner_model") # custom-trained model
# Catalog lookup tables (in production: backed by Redis or similar)
BRAND_LOOKUP = {
"nike": "brand_8421",
"adidas": "brand_8422",
"reebok": "brand_8423",
}
CATEGORY_LOOKUP = {
"running shoes": "cat_running",
"sneakers": "cat_running", # synonym mapping at link time
"trail shoes": "cat_trail",
}
def extract_and_link_entities(query: str) -> dict:
doc = nlp(query)
entities = {
"brands": [],
"categories": [],
"sizes": [],
"colors": [],
"gender": None,
}
for ent in doc.ents:
text = ent.text.lower().strip()
if ent.label_ == "BRAND":
linked = BRAND_LOOKUP.get(text)
if linked:
entities["brands"].append({"text": text, "id": linked})
elif ent.label_ == "CATEGORY":
linked = CATEGORY_LOOKUP.get(text)
if linked:
entities["categories"].append({"text": text, "id": linked})
elif ent.label_ == "SIZE":
entities["sizes"].append(text)
elif ent.label_ == "COLOR":
entities["colors"].append(text)
elif ent.label_ == "GENDER":
entities["gender"] = text
return entities
# Example usage
query = "nike air max 270 size 10 mens"
entities = extract_and_link_entities(query)
# Expected:
# {
# 'brands': [{'text': 'nike', 'id': 'brand_8421'}],
# 'categories': [],
# 'sizes': ['10'],
# 'colors': [],
# 'gender': 'mens'
# }
# Convert entities to retrieval filters/boosts
def entities_to_query_clauses(entities):
clauses = {"filter": [], "boost": []}
for brand in entities["brands"]:
clauses["filter"].append({"term": {"brand_id": brand["id"]}})
if entities["gender"]:
clauses["filter"].append({"term": {"gender": entities["gender"]}})
for size in entities["sizes"]:
clauses["filter"].append({"term": {"size": size}})
return clausesSection F — Query expansion patterns
Manual synonyms, co-click expansion, embedding-based expansion, LLM-generated expansion
Chapter 5 of Part 1 covered the query expansion approaches conceptually. This section makes them concrete patterns with operational depth. The patterns are typically combined in production deployments — each handles cases the others miss.
Synonym management and query expansion strategies #
Source: Lucene SynonymGraphFilter; Word2Vec (Mikolov et al., 2013); modern embedding-based expansion; LLM-based expansion patterns; Grainger on synonyms in AI-Powered Search
Classification — Methods for bridging vocabulary gaps between query terms and document terms.
Expand queries (or documents) with related terms so matches succeed despite vocabulary mismatch between user queries and document content, using a combination of manual, learned, and AI-generated synonym sources.
Vocabulary mismatch is the dominant failure mode in lexical search. Users say "sneakers"; documents say "running shoes". Users say "TV"; documents say "television". Users say "pain reliever"; documents say "analgesic". Pure lexical match misses all of these. Vector retrieval handles many cases via semantic similarity in embedding space, but lexical match remains foundational (Vol 1 Section A), and explicit synonyms still matter for cases the embeddings don't handle well — acronyms, brand variations, specific terminology.
Manual synonym lists. Curated mappings between terms: "shoes, sneakers, footwear" as a synonym group. The lists are applied in the analyzer chain (Section A) at index time or query time. Index-time expansion (apply synonyms when indexing documents) increases index size but produces no query-time overhead; query-time expansion (apply synonyms when processing queries) keeps the index lean but adds query-time work. Both are valid; the choice depends on whether the team prefers index-side or query-side complexity.
Synonym list construction. Domain experts identify high-value synonym pairs based on knowledge of the domain. The lists range from dozens (small workloads) to thousands (large e-commerce). Production teams typically maintain lists in version control with explicit review processes for changes — synonym changes affect every query and document, so changes warrant evaluation.
Bidirectional vs unidirectional synonyms. A bidirectional synonym ("shoes ↔ sneakers") means either term matches the other. A unidirectional synonym ("sneakers → shoes") means queries for sneakers also retrieve shoe documents, but queries for shoes don't retrieve sneaker-specific documents. Unidirectional handles broader-narrower relationships: "sneakers → shoes" works (sneakers are shoes) but "shoes → sneakers" wouldn't (not all shoes are sneakers).
Co-click expansion from logs. Mining production click logs for synonym pairs. Algorithm: for each query, find the set of documents that received clicks; for each pair of queries with overlapping click sets, compute the overlap fraction; queries with high overlap are candidate synonyms. The method captures actual user vocabulary at scale, including idiosyncratic terms (slang, regional variations) that manual curation might miss. Confidence thresholds matter: queries with only one or two shared clicks aren't reliable synonyms; the threshold should be tuned per workload.
Embedding-based expansion. Pre-trained embeddings (Word2Vec, GloVe, sentence-transformers) place semantically similar terms close in vector space. Find nearest neighbors of query terms in embedding space; consider them candidate synonyms. The method captures semantic similarity automatically but produces noise: "shoes" and "socks" are semantically related in many embedding spaces, but expanding a query for shoes to include socks is wrong. Filtering candidates by additional signals (co-occurrence in production data, manual review) improves precision.
LLM-generated expansion. Prompt an LLM with the query: "Generate 5 synonyms or closely-related terms for the query 'red running shoes' in an e-commerce context." The LLM produces context-aware expansions that earlier methods miss: multi-word phrases ("athletic footwear"), brand-specific terms, idiomatic equivalents. Production deployments precompute LLM expansions for high-volume queries (cache the results) and use real-time LLM calls only for unusual queries. The pattern handles edge cases that simpler methods struggle with.
Combining sources. Production deployments combine: manual synonyms for the high-value queries (the ones that drive substantial business value, where exact control matters); co-click expansion at scale (cheap, automatic, captures real usage); embedding expansion for cold-start cases (when click logs aren't available); LLM expansion for conversational queries where context matters. The combination produces broader coverage than any single method. Production teams typically version their synonym infrastructure separately from manual and learned synonyms, so changes can be tracked and reverted independently.
Evaluation. Synonym additions change retrieval behavior; they need evaluation. Methods from Volume 5: maintain golden query sets that exercise synonym-dependent queries; track precision and recall before/after synonym changes; A/B test substantial changes. Production teams without synonym evaluation typically accumulate synonym rules that individually seemed helpful but collectively degrade quality.
Almost every production search system uses some form of query expansion. E-commerce especially benefits from manual synonyms for the high-value queries plus co-click expansion at scale. Domain-specific search (legal, medical, technical) where standard terminology and user vocabulary differ benefits substantially. Multi-lingual search where translation-as-synonym handles cross-lingual matching.
Alternatives — pure vector retrieval that handles semantic similarity implicitly (Volume 1 Section B). Hybrid retrieval that combines lexical with semantic. Most production systems use synonyms even in hybrid setups because synonyms remain valuable for specific cases that pure vector retrieval handles imperfectly.
- Mikolov et al., "Efficient Estimation of Word Representations in Vector Space" (Word2Vec, 2013)
- Lucene SynonymGraphFilter documentation
- Elasticsearch / OpenSearch synonym documentation
- Grainger, AI-Powered Search, chapters on synonyms and expansion
Section G — Personalized query understanding
User context, session context, and locale as query disambiguation signals
The same query means different things to different users in different contexts. A query for "jaguar" from a cars enthusiast means the vehicle; from a wildlife enthusiast it means the animal. A session-based query for "mens" after "running shoes" means men's running shoes specifically. Personalized query understanding uses context signals to disambiguate. The pattern interacts with personalization in ranking (Volume 4 Section E); this section covers the query-understanding side.
Context-aware query understanding #
Source: Production methodology at major personalized search companies; emerging methodology on contextual NLP
Classification — Pattern for using user, session, and environmental context to disambiguate query understanding outputs.
Adjust query understanding outputs — intent classification, entity linking, synonym expansion — based on context signals about the user, session, and environment, producing per-user-per-context understanding that uniform understanding misses.
Query understanding without context produces a single interpretation that may not fit the user. "Jaguar" classified as informational without context could be about the car or the animal; the right answer depends on the user. "Mens" as a standalone query is ambiguous (gender? section? brand?); in session context after "running shoes" it's clearly a refinement. Context-aware understanding handles these cases; context-naive understanding doesn't.
Context signal sources. User-level: prior queries (does this user typically search for cars or animals?); prior purchases or interactions (a cars enthusiast has bought car-related products); demographic signals where legitimately available. Session-level: queries earlier in the session; filters or facets applied; categories of items viewed. Environmental: locale (different countries have different brand prevalence); time (some queries shift meaning by time of day); device (mobile users may shorten queries differently).
Context-aware intent classification. The intent classifier (Section D) takes the query plus context as input. The same query "jaguar" might be classified as transactional with high confidence in a cars-shopping session, and as informational in a wildlife-research session. Production implementations: include context features in the classifier's feature vector (rule-based and ML-based methods); include context in the LLM prompt for LLM-based classification.
Context-aware entity linking. When the query references an entity that could resolve to multiple IDs, context picks the right one. "Jaguar" in a car-shopping context links to brand_id_jaguar_motors; in a nature-research context links to species_id_jaguar. The disambiguation uses context features alongside the query span. Production implementations typically rank candidate links by combining base linking score (how well the surface form matches the ID) with context-adjusted scores.
Context-aware synonym selection. Some synonyms apply only in specific contexts. "Trainer" might mean running shoes in athletic context, but personal trainer in fitness-services context, but training data in ML context. Context-aware synonym selection chooses the appropriate expansion based on context. Implementation: maintain context tags on synonym rules; only apply rules whose tags match the query context.
Session-based query interpretation. Sequential queries in a session often build on each other. "Running shoes" → "mens" → "red" → "size 10" — each subsequent query refines the previous. Production patterns: maintain session context across queries; merge subsequent queries with the session context for retrieval (each query effectively appends to the context). The user experiences progressive narrowing; the system handles each query in light of what came before.
Cold-start and degradation. New users without history, anonymous sessions, no available context: context-aware understanding needs to degrade gracefully. Fall back to context-naive understanding. Use weak available signals (locale, device) cautiously. Build up session context as queries accumulate.
Privacy considerations. Context use can feel intrusive if users perceive that the system is making assumptions about them. Best practice: keep context use visible when possible ("showing results for cars" when the system inferred cars from session context); allow easy override ("search for jaguar in nature topics instead"); avoid context use that the user couldn't consent to (using inferred demographic signals to disambiguate). The discipline overlaps with broader personalization ethics from Volume 4 Section E.
Production search where queries are commonly ambiguous and context signals are available. E-commerce with logged-in users where session and purchase history disambiguate. Consumer search where session context strongly informs intent. Multi-domain search where domain context disambiguates entity references.
Alternatives — context-naive understanding for narrow domains where queries are unambiguous. Light context use (locale only) for privacy-sensitive deployments. The right level of context use depends on the workload and the privacy/ethics considerations specific to the deployment.
- Production methodology writings on contextual query understanding
- Coveo personalization and context documentation
- Algolia personalization and rules documentation
Section H — Discovery and resources
Where to track query understanding discipline as the field continues to evolve
Query understanding draws from NLP, IR, and ML literature. The discipline continues to evolve — LLM-based query understanding is changing what's practical; multilingual query understanding is becoming more sophisticated; structured-query understanding is improving. Staying current requires tracking multiple sources.
Resources for tracking query understanding discipline #
Source: Multiple academic, practitioner, and tool sources
Classification — Sources for staying current on query understanding practice.
Provide pointers to the active sources of query understanding knowledge across NLP, IR, ML, and production practice.
Query understanding spans multiple disciplines, each with its own literature and tools. Production teams need engagement with each to stay current.
Foundational texts. Jurafsky and Martin, Speech and Language Processing (3rd edition, free online drafts at web.stanford.edu/~jurafsky/slp3/) — the canonical NLP textbook covering tokenization, NER, classification, and modern transformer methods. Manning, Raghavan, Schütze, Introduction to Information Retrieval (free online) — ch. 2 on text processing, ch. 3 on tolerant retrieval (spell correction). Grainger, AI-Powered Search (Manning, 2024) — strong production-focused chapters on query understanding for modern search.
Academic conferences. ACL (Association for Computational Linguistics), EMNLP (Empirical Methods in NLP), NAACL (North American ACL) — the NLP venues where most query understanding research appears. SIGIR for the IR side. The NLP venues have grown enormously through 2020–2026; tracking the proceedings requires selection criteria (focus on papers about search-specific NLP, query processing, dialogue understanding).
Industry venues. Haystack Conference covers query understanding alongside other search topics. Berlin Buzzwords and adjacent search/data conferences. NLP-focused industry conferences (Spark + AI Summit, MLOps World) cover the NLP infrastructure side.
Practitioner writing. Daniel Tunkelang on query understanding and personalization. OpenSource Connections content on production NLP for search. Search team blogs at Etsy, Wayfair, Spotify, GitHub, and others periodically publish substantial query-understanding case studies.
Tools and libraries. spaCy (spacy.io) — production NLP including NER, tokenization, language detection. Hugging Face transformers — modern transformer-based NLP including NER, classification. Stanford CoreNLP — classical NLP toolkit. NLTK — educational and research NLP. Apache OpenNLP — Java-based NLP. Jellyfish — Python phonetic algorithms. For production search platforms: Elasticsearch / OpenSearch / Solr analyzer documentation; Coveo query pipeline documentation; Algolia query rules documentation.
Embedding and language models. Hugging Face Model Hub (huggingface.co/models) for pretrained models. MTEB leaderboard for embedding model comparison. Anthropic, OpenAI, Cohere, Voyage AI documentation for commercial LLM and embedding APIs. The space moves quickly through 2024–2026; tracking model releases and capabilities requires ongoing attention.
Datasets. CoNLL-2003 — the canonical NER benchmark. OntoNotes — multi-domain NER. MS MARCO and similar query datasets for query understanding context. Domain-specific NER datasets where available.
Communities. Hugging Face forums for transformer-based NLP. spaCy community. Relevancy Engineering Slack (via OpenSource Connections invitation) for search-specific discussion. Reddit r/LanguageTechnology for NLP community.
Emerging areas. LLM-based query understanding continues to evolve; the methodology for combining LLMs with traditional pipeline stages is consolidating. Multilingual query understanding is improving as multilingual LLMs mature. Structured query understanding (slot filling, semantic parsing) is benefiting from LLM advances. Conversational query understanding (handling multi-turn queries with context) is becoming a distinct subdiscipline.
Search engineers building or maintaining query understanding pipelines. Engineers transitioning into search from adjacent fields (data engineering, ML engineering, application development) who need to learn the discipline. Continuous education as the field evolves.
Alternatives — specialized consulting for high-stakes engagements. Internal documentation for teams with mature practice. The combination of external tracking and internal knowledge is the working pattern.
- Jurafsky and Martin, Speech and Language Processing (free online drafts)
- Manning et al., Introduction to Information Retrieval (free online)
- Grainger, AI-Powered Search (2024)
- spaCy documentation (spacy.io); Hugging Face transformers
- ACL/EMNLP/NAACL proceedings; SIGIR proceedings
- Haystack Conference (haystackconf.com)
- Relevancy Engineering Slack
Appendix A — Pattern Reference Table
Cross-reference of the query understanding patterns covered in this volume, what each provides, and when to use each.
| Pattern | Provides | When to use | Section |
|---|---|---|---|
| Lucene analyzer chain | Tokenization foundation | All lexical search | Section A |
| Edit-distance spell correction | Recover misspellings | Most consumer search | Section B |
| Phonetic spell correction | Catch sound-alike errors | Combined with edit-distance | Section B |
| Query rewriting (stop words, etc.) | Improve match quality | Diverse query workloads | Section C |
| Intent classification (rules+ML+LLM) | Routing signal | Heterogeneous queries | Section D |
| NER and entity linking | Structured signals | Domain queries with structure | Section E |
| Manual synonym lists | High-value vocabulary bridging | E-commerce, domain search | Section F |
| Co-click query expansion | Learned vocabulary bridging | Production at scale | Section F |
| Embedding-based expansion | Cold-start semantic similarity | When click logs unavailable | Section F |
| LLM-generated expansion | Context-aware expansion | Conversational queries | Section F |
| Context-aware QU | Per-user disambiguation | Logged-in users with history | Section G |
Appendix B — The Search Engineering Series
This catalog is Volume 2 of the Search Engineering Series. The current state of the series:
- Volume 1 — The Search Patterns Catalog (delivered) — query-time architectural patterns.
- Volume 2 — The Query Understanding Catalog (this volume) — the methods that produce the structured signals downstream stages consume.
- Volume 3 — The Indexing and Document Engineering Catalog (planned) — analyzers, field design, enrichment, chunking, embedding strategies.
- Volume 4 — The Ranking and Relevance Catalog (delivered) — scoring functions, learning to rank, neural rerankers, feature engineering.
- Volume 5 — The Search Evaluation Catalog (delivered) — metrics, judgment collection, online evaluation.
- Volume 6 — The Search Operations Catalog (planned) — tuning workflows, query log analysis, regression investigation.
- Volume 7 — The Search UX Patterns Catalog (planned) — autocomplete, facets, snippets, did-you-mean.
- Volume 8 — The Search Platforms Survey (planned) — Elasticsearch, OpenSearch, Solr, Coveo, Algolia, Vespa, Vertex AI Search, Typesense.
- Volume 9 (optional) — The Semantic and Vector Search Catalog (planned).
With Volume 2 delivered, the series has four of its planned core volumes (1, 2, 4, 5). The remaining high-priority volumes are 3 (Indexing and Document Engineering) and 6 (Search Operations). Volume 3 is the strongest next candidate because document-side processing mirrors query-side processing (analyzer chains from this volume's Section A apply both at query time and index time) and the relationship is natural to cover next. Volume 6 (Operations) is the alternative if day-to-day tuning workflow is more pressing in current client work.
Appendix C — Relationship to Volumes 1, 4, and 5
Volume 2 sits at the start of the query pipeline. Volume 1 documented the architectures that consume query understanding output; Volume 4 documented the ranking methods that use query understanding signals as features; Volume 5 documented the evaluation methods that measure outcomes. The four volumes interact at specific touchpoints.
Touchpoints with Volume 1 (Search Patterns). Volume 1 Section A (lexical retrieval) depends entirely on the analyzer chain documented in this volume's Section A. Volume 1 Section E (query routing) consumes the intent classification output from this volume's Section D. Volume 1 Section F (personalization in routing) uses the context-aware query understanding from this volume's Section G.
Touchpoints with Volume 4 (Ranking and Relevance). Volume 4 Chapter 3 (feature categories) identified four categories of features; query understanding produces signals in three of them: query features (query length, intent class, query embedding), query-document features (entity matches, synonym matches), context features (user context, session context). The features documented in Volume 4 depend on query understanding outputs documented here. Specifically: intent classification features (Volume 4 Section C) come from this volume's Section D; entity features come from this volume's Section E; expanded query terms come from this volume's Section F.
Touchpoints with Volume 5 (Search Evaluation). Volume 5 Section A (judgment lists) implicitly assumes that the queries in the judgment list have been processed through query understanding before retrieval; the judgment quality depends on consistent query processing. Volume 5 Section F (regression detection) often catches query understanding regressions as ranking regressions — a tokenization change that affects matching shows up as NDCG drops. Investigating Volume 5's alert outputs often leads back to Volume 2's patterns.
The reader path. A reader new to search engineering benefits from Volume 1 first (architecture), Volume 2 second (the front of the pipeline), Volume 4 third (the back of the pipeline), Volume 5 fourth (measurement). Or starting from any single volume and reading siblings as needed. Each volume can be read independently for its specific focus; the catalog as a whole supports comprehensive search engineering practice.
Appendix D — Discovery and Standards
Resources for tracking query understanding discipline (consolidated from Section H):
- Foundational texts: Jurafsky and Martin, Speech and Language Processing (free online drafts); Manning et al., Introduction to Information Retrieval (free online); Grainger, AI-Powered Search (Manning, 2024).
- Academic conferences: ACL, EMNLP, NAACL for NLP-side methods; SIGIR for IR-side methods.
- Industry venues: Haystack Conference, Berlin Buzzwords.
- Practitioner writing: Daniel Tunkelang, OpenSource Connections, search team blogs.
- Tools and libraries: spaCy, Hugging Face transformers, Stanford CoreNLP, Apache OpenNLP, NLTK, Jellyfish (phonetic).
- Search platforms: Elasticsearch / OpenSearch / Solr analyzer documentation; Coveo query pipeline; Algolia query rules.
- Embedding/LLM resources: Hugging Face Model Hub; MTEB leaderboard; Anthropic/OpenAI/Cohere/Voyage AI documentation.
- Datasets: CoNLL-2003 (NER); OntoNotes; MS MARCO; domain-specific datasets where available.
Three practical recommendations. First, spaCy and Hugging Face transformers provide most of the production NLP toolkit; investing in fluency with these two saves significant engineering effort. Second, the Lucene analyzer documentation is dense but worth reading carefully — the analyzer chain is the foundation of lexical search, and understanding it well prevents many production bugs. Third, query log analysis is the underutilized practitioner skill in query understanding; the patterns that need attention are typically visible in production data once someone looks. The future Volume 6 (Operations) will cover query log analysis methodology in depth.
Appendix E — Omissions
This catalog covers about 11 patterns across 8 sections — the scope of a structural volume on query understanding. The wider discipline includes much that isn't covered here:
- Multi-turn conversational query understanding in depth (handling pronouns and references across turns, dialogue state tracking). Bridges to agentic AI; emerging methodology.
- Cross-lingual query understanding (queries in one language matching documents in another). Specialized topic; deserves dedicated treatment.
- Voice-input query understanding (transcription errors, prosody handling, conversational features of voice queries). Bridges to speech recognition; specialized.
- Query understanding for code search and other specialized domains. Each has its own conventions and methodology.
- Question answering pipelines that consume query understanding output. Bridges to RAG and agentic AI.
- Adversarial query understanding (handling queries designed to evade or game the system). Security territory.
- Query log analytics methodology in depth (zero-result analysis, low-CTR query investigation). Planned Volume 6 (Operations).
- Fairness and bias in query understanding (does the system handle queries from different demographic groups equally well?). Important emerging area.
- Privacy-preserving query understanding (federated learning, on-device processing). Specialized topic with regulatory drivers.
- Specific platform query-understanding tooling comparison (Coveo vs Algolia vs Vertex AI Search). Planned Volume 8 (Platforms Survey).
Appendix F — The Core Series Quartet
With Volume 2 delivered, the Search Engineering Series has its core quartet: Volume 1 (architectures), Volume 2 (front-of-pipeline), Volume 4 (back-of-pipeline), Volume 5 (measurement). The four volumes together cover the complete query-time pipeline plus the methodology for measuring its outcomes. A practitioner with all four volumes has structural reference for end-to-end production search engineering practice.
The quartet covers what most production search teams need most. Volume 1 establishes the architectural vocabulary; Volume 2 covers the query-side processing that's most often underdeveloped; Volume 4 covers the ranking methods that most often drive quality gains; Volume 5 covers the evaluation discipline that prevents silent quality degradation. The four volumes can be used as a working library across many search engagements.
What's missing from the quartet. Indexing and document engineering (Volume 3) is the obvious gap — the document-side processing that mirrors and depends on the query-side processing in this volume. Operations (Volume 6) is the next obvious gap — the day-to-day tuning workflow that integrates the methodologies from the other volumes. Together Volumes 3 and 6 would complete the production-engineering side of the series. UX Patterns (Volume 7) and Platforms Survey (Volume 8) round out the broader coverage.
The discipline of stopping. Each subsequent volume should earn its place. The catalog's value rests on each volume contributing structural reference that justifies its existence. If a future volume would be a less-than-essential repetition of material from textbooks or other catalogs, it shouldn't be written. The current four volumes do justify themselves; future volumes need to clear the same bar.
Consulting application. For practitioners working with clients, the quartet maps to consulting deliverables in a structured way: Volume 1 frames the architectural choices; Volume 2 covers the query-side investigation that typically reveals the largest gaps; Volume 4 frames the ranking-method choices; Volume 5 anchors the evaluation discipline that justifies the investments. Engagements that touch any of these areas have direct reference material; engagements that span multiple areas can use the volumes together.
— End of The Query Understanding Catalog (Volume 2) —
— Volume 2 of the Search Engineering Series —